
분산 추적 모니터링이 끊기는 문제
서비스 아키텍처와 발생한 문제
전처리 서비스의 아키텍처는 역할 분리로 설계되어 있습니다:
- API 서버: 전처리 요청 수신
- Batch 서버: 이벤트 발행
- Worker (Kafka): 실제 분석 수행
전처리 서비스는 사내 검색엔진을 통해 처리가 됩니다.
하지만 이 검색엔진은 받을 수 있는 트래픽이 작동하는 Worker의 수에 따라 한정이 되어있었고 이 트래픽을 통제하기 위해 사내에서 운영중인 Kafka를 활용하여 처리합니다.
마주친 문제
비동기로 변경하면서 모니터링에 심각한 문제가 발생했습니다:
- API 서버에서
trace-id가 생성되어 처음에는 정상 추적됨 - 하지만 Batch 서버에서 이벤트를 발행할 때, 새로운 trace-id가 생성됨 ❌
- Worker 서버도 또 다른 trace-id를 가짐
- 결과적으로 API → Batch → Worker의 전체 흐름이 세 개의 서로 다른 trace로 분리됨
즉, “API 요청이 어느 분석까지 영향을 미쳤는가?”를 추적할 방법이 없었습니다.
문제의 본질
이 문제의 근본 원인은 간단했습니다:
Batch 서버가 API 서버의 Trace Context를 모르고 있다.
Batch는 DB에서만 이벤트 정보를 읽을 뿐, “이 이벤트가 어느 API 요청에서 나온 것인가”를 알 수 없었습니다. 따라서 trace-id를 이어줄 수 없었습니다.
Trace Context를 DB에 저장하고 복원
Datadog Trace Context란?
Trace Context는 Datadog에서 분산 추적을 위해 정의한 메타데이터입니다.
이것을 이용하면, 서로 다른 서버 간에 “어느 원본 요청에서 나온 작업인가”를 이어줄 수 있습니다.
참고: Datadog 공식 문서
Trace Context의 구성 요소
Trace Context에는 여러 값들이 있습니다:
x-datadog-trace-id- 의미: 전체 요청 흐름을 식별하는 고유한 추적 ID
- 용도: 하나의 사용자 요청이 여러 마이크로서비스를 거쳐가더라도 동일한 trace-id로 연결하여 전체 흐름을 추적
- 형태: 64비트 또는 128비트 정수 (보통 16진수로 표현)
x-datadog-parent-id- 의미: 현재 span의 부모 span ID
- 용도: 서비스 간 호출 관계와 계층 구조를 구성하는 데 사용
- 형태: 64비트 정수
x-datadog-origin- 의미: 추적이 시작된 원점/소스를 나타냄
- 용도: 추적의 출발점이 어디인지 식별 (예: ‘synthetics’, ‘rum’, ‘lambda’ 등)
- 예시:
synthetics,rum,lambda,profiling
x-datadog-sampling-priority- 의미: 해당 추적의 샘플링 우선순위
- 용도: 추적 데이터를 얼마나 중요하게 처리할지 결정
- 값:
-1: 자동 거부 (DROP)0: 자동 유지 (AUTO_REJECT)1: 자동 유지 (AUTO_KEEP)2: 사용자 유지 (USER_KEEP)
x-datadog-tags- 의미: 추적과 관련된 메타데이터 태그들
- 용도: 추적에 추가적인 컨텍스트 정보를 부여 (환경, 버전, 사용자 ID 등)
- 형태: 키-값 쌍들이 URL 인코딩된 형태 (예:
_dd.p.key1=value1,key2=value2)
구현 전략: “추출 → 저장 → 복원”
제가 세운 전략은 간단합니다:
- API 서버에서 Trace Context 추출 - 현재 요청의 trace-id 등을 추출
- DB에 저장 - 이 trace 정보를 함께 저장
- Batch/Worker에서 복원 - 저장된 trace 정보를 읽어 사용
이렇게 하면 서버 간 통신이 없어도 trace-id를 이어줄 수 있습니다.
구현 1단계: Trace Context 추출 및 복원 유틸 작성
의존성 추가
api 'com.datadoghq:dd-trace-ot:1.46.0'
api 'com.datadoghq:dd-trace-api:1.46.0'
TraceUtil: 추출과 복원을 담당하는 유틸리티
Trace Context 추출 - API 서버에서 사용
public static Map<String, String> extractTraceContext() {
Tracer tracer = getTracer();
Span span = getSpan();
if (Objects.isNull(span)) {
return Collections.emptyMap();
}
Map<String, String> contextMap = new HashMap<>();
tracer.inject(span.context(), Format.Builtin.TEXT_MAP, new TextMapAdapter(contextMap));
return contextMap;
}
Trace Context 복원 - Batch/Worker 서버에서 사용
복원할 때의 핵심은 부모 context를 명시하는 것입니다. 이렇게 하면 Datadog이 자동으로 “이 span은 저 span의 자식”이라고 인식합니다.
public static Span createSpanFromContext(String operationName, Map<String, String> contextMap) {
Tracer tracer = getTracer();
if (CollectionUtils.isEmpty(contextMap)) {
return tracer.buildSpan(operationName).start();
}
try {
SpanContext parentContext = tracer.extract(Format.Builtin.TEXT_MAP, new TextMapAdapter(contextMap));
if (Objects.nonNull(parentContext)) {
return tracer.buildSpan(operationName)
.asChildOf(parentContext) // ← 부모 context를 지정
.start();
}
} catch (Exception e) {
// Context 추출 실패 시 새로운 Span 생성
}
return tracer.buildSpan(operationName).start();
}
Span을 활성화하기
public static io.opentracing.Scope activateSpan(Span span) {
return getTracer().activateSpan(span);
}
Span을 활성화해야만 비즈니스 로직이 이 span에 포함됩니다. 활성화하지 않으면 로그, DB 쿼리 등이 이 span의 자식으로 기록되지 않습니다.
구현 2단계: Trace Context를 DB에 저장하기
이제 TraceUtil을 사용해서 Trace Context를 추출했으니, 이 정보를 DB에 저장해야 합니다.
Redis vs RDB 중 RDB 선택한 이유
처음엔 Redis를 고려했습니다. 메모리에서 빠르게 조회할 수 있거든요.
하지만:
- 현재 서비스에서 Redis를 사용하지 않음
- Trace Context 하나만을 위해 Redis를 도입할 경험 비용이 너무 높음
따라서 RDB에 저장하기로 결정했습니다.
저장 전략
Trace Context를 저장할 위치:
- Aggregate Root 저장 시 (PreprocessJob 생성)
- API 서버에서 수신한 요청의 trace context 저장
- Outbox 테이블에도 저장 (이벤트 발행 시)
- 이유: Batch 서버가 이벤트를 읽을 때마다 Aggregate Root를 다시 조회하는 비효율 제거
- Outbox와 함께 저장하면 한 번에 모든 정보를 읽을 수 있음
실제 구현 예시
@Slf4j
@Service
@RequiredArgsConstructor
public class PreprocessJobCreateService {
//...의존성 코드
@Transactional
public PreprocessJob create(CreatePreprocessJobCommand command) {
TraceContext traceContext = new TraceContext(TraceUtil.extractTraceContext());
PreprocessJob preprocessJob = PreprocessJob.create(
//.. 기타 필드
traceContext
);
// Aggregate Root
PreprocessJob savedJob = preprocessJobRepository.save(preprocessJob);
//outbox
outboxRepository.save(PreprocessJobCreatedOutbox.create(savedJob, traceContext));
return savedJob;
}
구현 3단계: 저장된 Trace Context 복원하기
이제 Batch/Worker 서버에서 저장된 Trace Context를 읽어 복원해야 합니다.
TraceContext: Value Object로 설계
Trace Context에서 특정 값을 추출하는 로직이 많아서 Value Object로 만들었습니다. 이렇게 하면 trace-id 추출, 유효성 검증 등을 한 곳에 모을 수 있습니다.
TraceContext.java
public record TraceContext(Map<String, String> value) {
private static final String TRACE_ID_KEY = "x-datadog-trace-id";
public String getTraceId() {
if (value.containsKey(TRACE_ID_KEY)) {
return value.get(TRACE_ID_KEY);
}
return "";
}
}
Batch 서버에서 Trace Context 복원
이제 저장된 Trace Context를 읽어 복원하는 코드입니다:
@Slf4j
@Service
@RequiredArgsConstructor
public class ExtractSentenceService {
// ...
public void extract(SentenceExtractCommand command) {
// 1. DB에서 PreprocessJob 조회 (Trace Context 포함)
PreprocessJob job = jobReader.readById(jobId);
TraceContext traceContext = job.getTraceContext();
// 2. 저장된 Trace Context로부터 Span 복원
Span span = TraceUtil.createSpanFromContext("extract sentence", traceContext.value());
// 3. Span을 활성화 (try-with-resources로 자동 관리)
try (Scope scope = TraceUtil.activateSpan(span)) {
// 비즈니스 로직
// (이 안의 모든 DB 쿼리, 로그가 이 span의 자식으로 기록됨)
} finally {
// 4. Span 종료
span.finish();
}
}
}
핵심:
TraceContext.value()는 저장된 trace 정보가 담긴 MapcreateSpanFromContext()가 부모 context를 복원하면서 trace-id를 유지activateSpan()으로 활성화해야 비즈니스 로직이 이 span에 포함됨
개선: AOP로 보일러플레이트 제거하기
발견한 문제
위 코드를 보면 trace 관련 코드가 모든 메서드에 반복됩니다:
try (Scope scope = TraceUtil.activateSpan(span)) {
// 비즈니스 로직
} finally {
span.finish();
}
이렇게 되면 비즈니스 로직이 trace 코드에 묻혀버립니다. 개발자는 핵심 로직에 집중하기 어렵습니다.
해결책: AOP Annotation으로 관심사 분리
AOP를 사용하면 trace 로직을 메서드 밖으로 빼낼 수 있습니다.
1단계: Annotation 정의
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DatadogTrace {
String operationName() default ""; // Trace에 남길 작업명
}
2단계: AOP 구현
하지만 AOP에서 TraceContext를 어떻게 가져올까? 두 가지 방법을 고민했습니다:
방법 1: Spring Expression Language (SpEL)
- 장점: 유연함
- 단점: 문자열로 직접 작성 → 오타 실수, 유지보수 어려움, Parser 필요
방법 2: 인터페이스 기반 추상화 ✅ (선택)
- 장점: 타입 안전, IDE 자동완성, 오류 조기 발견
- 단점: 도메인 객체가 인터페이스를 구현해야 함
저는 방법 2를 선택했습니다. 번거로움보다 안정성이 훨씬 더 중요하기 때문입니다.
구현: TraceContextProvider 인터페이스
public interface TraceContextProvider {
TraceContext traceContext();
}
이 인터페이스를 구현하는 도메인 객체:
@Getter
public class PreprocessJob implements TraceContextProvider {
// ...
private TraceContext traceContext;
@Override
public TraceContext traceContext() {
return this.traceContext;
}
}
Aspect에서 자동 추출
이제 AOP의 @Around에서 자동으로 TraceContext를 찾을 수 있습니다:
@Aspect
@Component
@Slf4j
public class DatadogTraceAspect {
@Around("@annotation(datadogTrace)")
public Object traceSpan(ProceedingJoinPoint joinPoint, DatadogTrace datadogTrace) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
Object[] args = joinPoint.getArgs();
String operationName = determineOperationName(datadogTrace, method);
TraceContext traceContext = extractTraceContextFromArgs(args); // ← 자동 추출
Span span = TraceUtil.createSpanFromContext(operationName, traceContext.value());
try (Scope scope = TraceUtil.activateSpan(span)) {
return joinPoint.proceed();
} finally {
span.finish();
}
}
private String determineOperationName(DatadogTrace datadogTrace, Method method) {
return Optional.ofNullable(datadogTrace.operationName())
.filter(name -> !name.isBlank())
.orElse(method.getDeclaringClass().getSimpleName() + "." + method.getName());
}
private TraceContext extractTraceContextFromArgs(Object[] args) {
// 메서드 인자 중 TraceContextProvider를 구현한 객체 찾기
return Arrays.stream(args)
.filter(TraceContextProvider.class::isInstance)
.map(TraceContextProvider.class::cast)
.findFirst()
.map(TraceContextProvider::traceContext)
.orElse(new TraceContext(TraceUtil.extractTraceContext()));
}
}
동작 원리:
- 메서드 인자 중에
TraceContextProvider를 구현한 객체가 있으면 자동으로 추출 - 없으면 현재 Trace Context를 새로 생성 (API 서버)
operationName이 비어있으면 “클래스명.메서드명”으로 자동 생성
사용 방법이 얼마나 간단한가?
이제 개발자가 해야 할 일:
@DatadogTrace(operationName = "extract sentence")
public void extract(PreprocessJob job) {
// 비즈니스 로직만 집중!
// Trace 관련 코드는 AOP가 자동으로 처리
}
Trace 코드가 완전히 사라졌습니다! 개발자는 비즈니스 로직에만 집중할 수 있습니다.
추가 개선: 예외 처리 및 에러 추적
문제: 예외가 발생하면?
현재 코드는 정상 실행만 처리합니다. 예외가 발생하면 어떻게 될까요?
Datadog에서 에러를 추적하려면 Span에 에러 정보를 태그로 추가해야 합니다.
예외 처리 추가
@Around("@annotation(datadogTrace)")
public Object traceSpan(ProceedingJoinPoint joinPoint, DatadogTrace datadogTrace) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
Object[] args = joinPoint.getArgs();
String operationName = determineOperationName(datadogTrace, method);
TraceContext traceContext = extractTraceContextFromArgs(args);
Span span = TraceUtil.createSpanFromContext(operationName, traceContext.value());
try (Scope scope = TraceUtil.activateSpan(span)) {
return joinPoint.proceed();
} catch (Throwable throwable) {
// ← 예외 발생 시 에러 정보를 span에 기록
span.setTag("error", true);
span.setTag("error.msg", throwable.getMessage());
span.setTag("error.kind", throwable.getClass().getSimpleName());
span.setTag("error.stack", getStackTrace(throwable));
span.setTag("method.name", method.getName());
span.setTag("class.name", method.getDeclaringClass().getSimpleName());
throw throwable; // 원본 예외 재발생 (중요!)
} finally {
span.finish(); // 예외 발생 여부와 관계없이 항상 종료
}
}
private String getStackTrace(Throwable throwable) {
StringWriter sw = new StringWriter();
throwable.printStackTrace(new PrintWriter(sw));
return sw.toString();
}
결과:
- Datadog UI에서 에러 표시 ✓
- 스택트레이스 포함 ✓
- 원본 예외는 정상적으로 전파 ✓
결과
실제 결과
이제 API 요청을 하면:
POST /preprocessor-api/request
Datadog UI에서 확인할 수 있습니다:
- API 서버: trace-id 생성 → Trace Context 저장
- Batch 서버: 저장된 Trace Context 읽음 → 같은 trace-id로 이어짐
- Worker 서버: Batch의 trace-id를 상속 → 완전한 trace chain 형성
결과: 하나의 trace-id로 API → Batch → Worker 전체 흐름을 추적 가능! ✓
스크린샷 예시
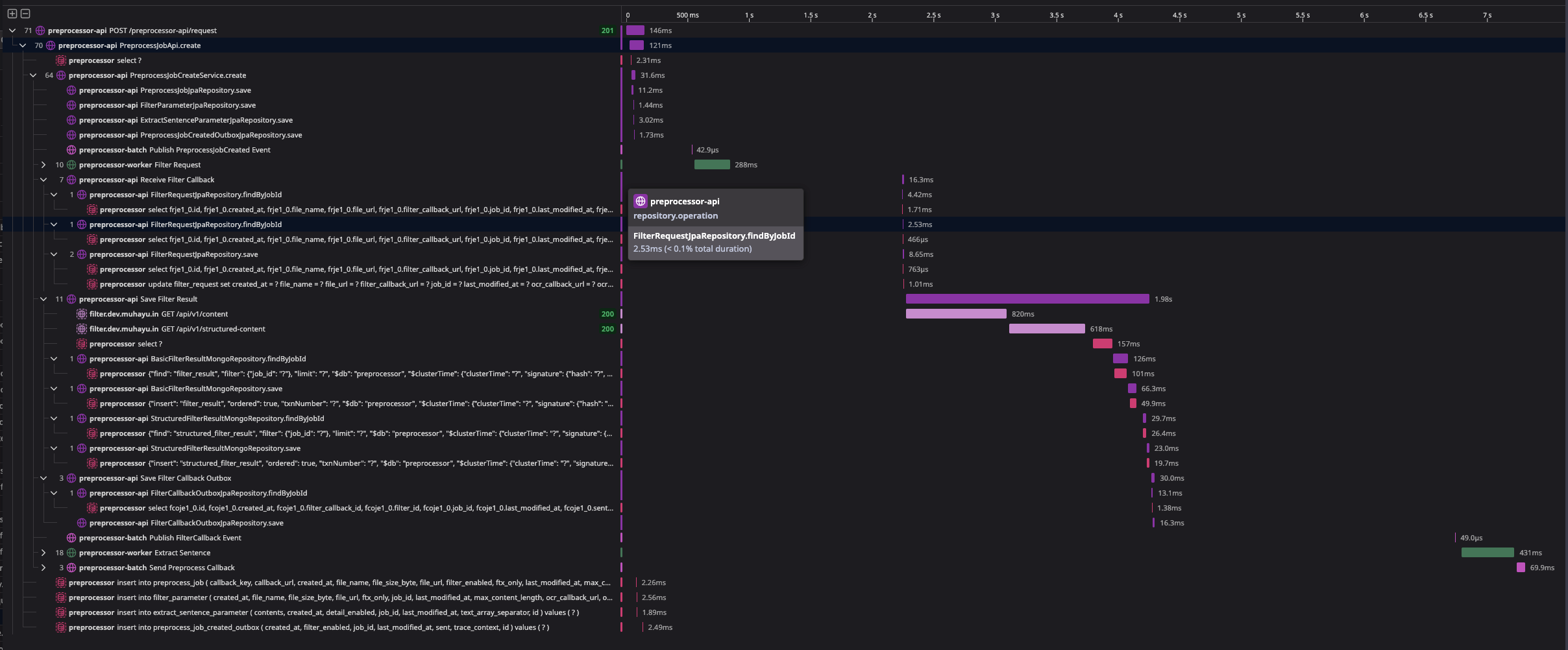

회고: 이 구현을 통해 배운 점
1. 아키텍처와 모니터링의 관계
아키텍처가 모니터링 전략을 결정합니다.
비동기 아키텍처로 변경되니 자동으로 이어지던 trace가 끊겼습니다. 결국 “서버 간 데이터를 어떻게 전달할 것인가”가 trace 전파 방식을 결정하는 것입니다.
2. “저장하고 복원하기”의 강력함
HTTP 헤더로 trace context를 전달할 수 없는 상황에서도, DB에 저장하고 나중에 복원함으로써 trace를 이어줄 수 있었습니다.
이 패턴은 다른 많은 문제에도 적용할 수 있을 것 같습니다.
3. AOP의 진정한 가치
처음엔 “trace 코드는 복잡하니까 AOP로 감싸자”라고 생각했는데, 실제로 얻은 건 더 컸습니다:
개발자가 비즈니스 로직에만 집중할 수 있게 했다는 것이 가장 큰 수확입니다.
4. 선택의 기준: “번거로움 vs 안정성”
SpEL vs 인터페이스 기반 추상화 중에서 선택할 때, 문자열 기반의 유연함보다 타입 안전성을 선택했습니다.