
캐시
캐시라고 하면 흔하게 어떤 데이터를 매번 직접 요청하여 가져오는 것이 아니라 공부할 때 벽에 붙여놓는 포스트잇 처럼 빈번하게 찾아야하는 정보를 찾기 빠른 곳에 저장해두고 조회하는 방식을 의미합니다.
하지만 인터넷에는 여러 캐시 전략들이 존재하는 걸 보고,
“단순히 빠르게 조회하기 위한 방식이면 다양할 이유가 없지 않을까?” 라는 생각이 들었습니다.
그렇다면 다양한 전략이 존재하는 이유는 뭘까요?
아마도 “모든 데이터가 같은 특성을 가지지 않기 때문”이 아닐까 생각했습니다.
어떤 데이터는 자주 조회되지만, 어떤 데이터는 자주 변경됩니다. 또 어떤 데이터는 실시간성이 중요하고, 어떤 데이터는 그렇지 않습니다.
그래서 저는 캐시 전략들을 살펴보고 이커머스 도메인에서 각 전략이 어떤 데이터 특성에 맞는지 고민해봤습니다.
Cache Aside
Cache Aside 전략은 데이터가 요청되면 캐시를 먼저 읽고 캐시에 데이터가 없으면 데이터베이스에서 검색하여 조회한 후에 다음에 조회 시 캐시에서 조회할 수 있도록 캐시에 저장합니다.
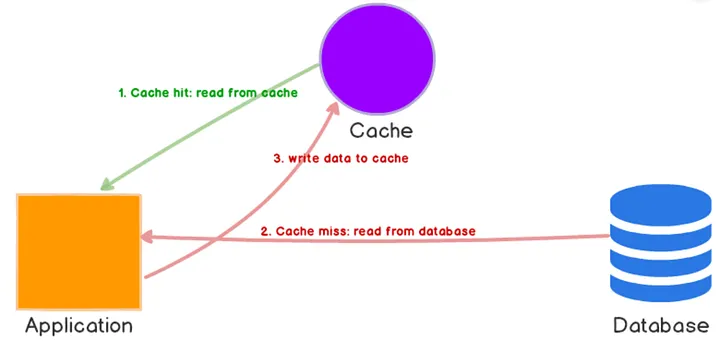
이 전략의 핵심은 “자주 조회되는 데이터를 특정할 수 있는가”입니다.
만약 조회 패턴이 명확하다면(예: 인기 상품 1000개가 전체 트래픽의 80%를 차지), Cache Aside는 매우 효과적입니다.
일례로 이커머스 도메인의 상품 상세 조회는 좋은 예시입니다.
인기 있는 상품들은 비인기 상품보다 훨씬 자주 조회되기 때문입니다.
실제로 이것이 얼마나 효과적인지 직접 테스트를 진행해봤습니다.
Cache Aside 테스트
아래는 기존의 상품 상세 조회의 코드입니다.
public ProductDetail getProductDetail(GetProductDetailQuery query) {
ProductId productId = new ProductId(query.getProductId());
Product product = productRepository.getById(productId);
Brand brand = brandRepository.getBrandById(product.getBrandId());
return new ProductDetail(product, brand);
}
단순히 상품의 ID로 상품을 조회하고, 상품의 브랜드 ID로 브랜드 정보를 조회해 상세 정보(ProductDetail)를 반환합니다.
이 코드를 캐시를 적용하여 아래와 같이 구현했습니다.
public ProductDetail getProductDetail(GetProductDetailQuery query) {
ProductId productId = new ProductId(query.getProductId());
return cacheRepository.findDetailBy(productId)
.orElseGet(() -> {
Product product = productRepository.getById(productId);
Brand brand = brandRepository.getBrandById(product.getBrandId());
ProductDetail productDetail = new ProductDetail(product, brand);
cacheRepository.save(productDetail);
return productDetail;
});
}
cacheRepository를 통해 상품 상세 정보를 조회한 후 존재하지 않는 경우 데이터베이스에서 조회, 캐시를 저장합니다.
이제 k6를 통해 부하테스트를 진행해봅시다.
테스트 환경을 설정할 때 매우 중요한 결정을 했는데, 바로 테스트 가정 설정입니다.
- 전체 상품: 100만 건
- 자주 조회되는 상품: 1000개 (상품의 0.1%)
- 테스트 방식: 이 1000개만 반복적으로 조회
왜 이렇게 설정했을까요?
실무에서 이커머스 서비스를 운영하면, 모든 상품이 동등하게 조회되지 않습니다.
인기 상품은 매일 수천 번 조회되지만, 니치한 상품은 일주일에 몇 번 조회되지 않을 수 있습니다.
이 비율이 Cache Aside 전략의 성공을 결정합니다.
테스트 스크립트는 다음과 같습니다.
import http from 'k6/http';
import {check, group} from 'k6';
export const options = {
stages: [
{duration: '10s', target: 1000}, // 1000명까지 10초에 증가
{duration: '30s', target: 1000}, // 1000명 유지 30초
{duration: '10s', target: 0}, // 10초에 감소
],
thresholds: {
http_req_duration: ['p(95)<500', 'p(99)<1000'],
http_req_failed: ['rate<0.1'],
},
};
const BASE_URL = 'http://localhost:8080';
export default function () {
group('기본 상품 상세 조회', () => {
const randomId = Math.floor(Math.random() * 1001);
const response = http.get(`${BASE_URL}/api/v1/products/${randomId}/detail`);
check(response, {
'status는 200': (r) => r.status === 200,
'응답 시간 < 500ms': (r) => r.timings.duration < 500,
});
});
}
0~10초간 VUs를 1000명까지 증가 시킨 후 30초간 1000VUs를 유지하고 남은 10초동안 VUs를 감소합니다.
봐야할 부분은 randomId값입니다. 랜덤한 1000개의 상품을 조회합니다.
이 말인 즉, 자주 조회되는 상품을 1000개 정도로 지정하겠다는 의미입니다.
테스트 결과
캐시 적용 전
HTTP
http_req_duration..............: avg=1.83s min=4.51ms med=1.75s max=4.25s p(90)=3.25s p(95)=3.36s
{ expected_response:true }...: avg=1.83s min=4.51ms med=1.75s max=4.25s p(90)=3.25s p(95)=3.36s
http_req_failed................: 0.07% 17 out of 22396
http_reqs......................: 22396 447.896512/s
캐시 적용 후
HTTP
http_req_duration..............: avg=46.31ms min=264µs med=46.05ms max=2.99s p(90)=71.51ms p(95)=81.25ms
{ expected_response:true }...: avg=46.26ms min=264µs med=46.04ms max=2.99s p(90)=71.46ms p(95)=81.18ms
http_req_failed................: 0.09% 803 out of 821803
http_reqs......................: 821803 16435.660942/s
결과 분석
테스트 결과를 비교해보겠습니다.
| 지표 | 캐시 적용 전 | 캐시 적용 후 | 개선율 |
|---|---|---|---|
| 평균 응답시간 | 1.83s | 46.31ms | 약 40배 |
| 최소 응답시간 | 4.51ms | 264µs | 약 17배 |
| P(90) | 3.25s | 71.51ms | 약 45배 |
| P(95) | 3.36s | 81.25ms | 약 41배 |
| 초당 처리량 | 447.9/s | 16,435.7/s | 약 37배 |
캐시 적용 후 평균 응답 시간이 1.83초에서 46.31ms로 약 40배 개선되었습니다.
특히 주목할 점은 초당 처리량이 약 37배 증가했다는 것입니다.
동시 사용자가 1000명으로 유지되는 상황에서, 기존에는 초당 447개의 요청만 처리했지만, 캐시 적용 후에는 초당 16,435개의 요청을 처리할 수 있게 되었습니다.
Write-Behind
Write-Behind 전략은 데이터를 요청 시 캐시에만 저장하고, 배치 작업을 통해 주기적으로 데이터베이스로 옮기는 전략입니다.
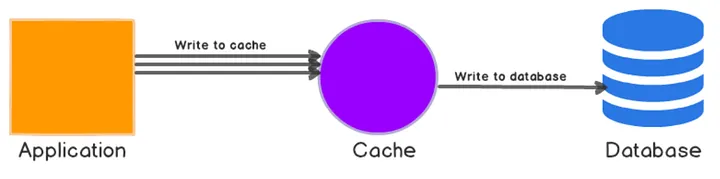
어떤 데이터에 적합할까?
Cache Aside와는 다릅니다. Write-Behind가 빛나는 데이터는 특정한 특성을 가지고 있습니다.
| 특성 | 설명 |
|---|---|
| 빈번한 변경 | 초 단위로 계속 쓰기가 발생 |
| 낮은 실시간성 | 데이터가 몇 초 또는 몇 분 정도 지연되어도 괜찮음 |
| 높은 쓰기 비용 | 데이터베이스 쓰기 작업이 많은 리소스 소비 |
이커머스 도메인에서 이 모든 특성을 가진 데이터는 뭘까요?
바로 “상품의 좋아요” 기능입니다.
- 매우 빈번함: 인기 상품은 초당 수십~수백 개의 좋아요 요청
- 실시간성 낮음: 사용자는 좋아요 수가 정확히 12,345개인지 12,346개인지 구분 못함
- DB 부하 심함: 매 요청마다 쓰기 + 트랜잭션 로그 + 인덱스 업데이트 = 상당한 비용
따라서 Write-Behind는 이 데이터에 거의 완벽하게 들어맞는 전략입니다.
기존 방식의 한계
먼저 데이터베이스만 사용한 기존 코드를 보겠습니다.
@Transactional
public void like(ProductLikeCommand command) {
User user = userRepository.getByIdentifier(new UserIdentifier(command.getUserIdentifier()));
Product product = productRepository.getByIdWithLock(new ProductId(command.getProductId()));
boolean isAlreadyLiked = productLikeRepository.findByUserIdAndProductIdWithLock(user.getId(), product.getId())
.isPresent();
if (!isAlreadyLiked) {
productLikeRepository.save(ProductLike.create(user.getId(), product.getId()));
productRepository.save(product.increaseLikeCount());
}
}
매번 요청할 때마다:
- 사용자 조회 (DB 읽기)
- 상품 조회 + 락 (DB 읽기)
- 중복 검사 (DB 읽기)
- 좋아요 저장 (DB 쓰기)
- 상품 좋아요 수 업데이트 (DB 쓰기)
초당 수백 건의 좋아요 요청이 들어온다면, 데이터베이스 쓰기 부하는 감당할 수 없는 수준이 됩니다.
Redis를 활용한 개선
그렇다면 어떤 자료구조를 사용할까요?
조건:
- 하나의 상품에 여러 사용자가 좋아요를 누름
- 중복된 좋아요는 불가능
- 최근 좋아요 순서도 추적하면 좋음
Sorted Set을 선택한 이유:
단순 Set 접근:
like:product:1001 = { 101, 102, 103, 105 }
└─ 문제: 어떤 사용자가 언제 좋아요 했는지 추적 불가
Sorted Set 접근:
like:product:1001 = {
101: 1700000000, ← 타임스탐프를 score로 사용
102: 1700000010,
103: 1700000020,
105: 1700000030
}
└─ 이점: "최근 1시간 좋아요 사용자", "최근 좋아요 상품" 등의 요구사항 대응 가능
최종 키 구조:
좋아요 데이터 (상품 기준):
like:product:1001 = { user_id: timestamp }
좋아요 데이터 (사용자 기준):
like:user:101 = { product_id: timestamp }
이중 저장으로 “이 사용자가 좋아요한 상품들” 같은 쿼리도 캐시에서 바로 처리할 수 있습니다.
핵심 아이디어: Like와 Unlike 분리
이제 코드를 보겠습니다.
@Transactional
public void like(ProductLikeCommand command) {
User user = userRepository.getByIdentifier(new UserIdentifier(command.getUserIdentifier()));
Product product = productRepository.getById(new ProductId(command.getProductId()));
long timestamp = System.currentTimeMillis();
ProductLikeCache likeCache = new ProductLikeCache(product.getId(), user.getId(), timestamp);
productLikeCacheRepository.saveLike(likeCache); // like 저장
productLikeCacheRepository.deleteUnlike(likeCache); // unlike 삭제
}
조금 이상해 보이나요? 좋아요를 취소할 때는 unlike를 저장합니다.
@Transactional
public void unlike(ProductLikeCommand command) {
// ...
productLikeCacheRepository.deleteUnlike(likeCache); // like 삭제
productLikeCacheRepository.saveLike(likeCache); // unlike 저장
}
왜 이렇게 복잡하게 할까요?
일반적으로는 이렇게 하고 싶을 겁니다:
좋아요 요청 → like:product:1001에서 user_id 제거
좋아요 취소 → like:product:1001에서 user_id 추가
하지만 배치 작업에서 문제가 발생합니다.
시간1: 사용자A가 좋아요 → like 데이터 저장 ✓
시간2: 사용자A가 좋아요 취소 → like 데이터 삭제 (캐시에서만) ✓
시간3: 배치 동기화 시작
배치가 보는 현재 캐시: 아무 데이터도 없음
배치가 할 수 있는 일: 아무것도 없음 ✗
결과: 데이터베이스에는 여전히 "사용자A의 좋아요"가 남음
이 문제를 해결하려면 “변경 이력”을 남겨야 합니다.
좋아요: like:product:1001에 저장
좋아요 취소: unlike:product:1001에 저장 ← 취소 이력 기록
배치는 이제 두 가지 데이터를 모두 봅니다:
- like 데이터: 새로 추가할 좋아요들
- unlike 데이터: 삭제할 좋아요들
따라서 배치가 데이터베이스에 정확히 반영할 수 있습니다.
배치 동기화: 증분 처리
이제 배치 로직을 보겠습니다.
@Transactional
public void sync() {
long currentTime = System.currentTimeMillis();
long lastSyncedTime = productLikeCacheRepository.getLastSyncTime();
// 마지막 동기화 이후의 데이터만 조회
List<ProductLikeCache> newCachedLikes = productLikeCacheRepository
.getLikesSinceLastSync(lastSyncedTime, currentTime);
List<ProductLikeCache> newCachedUnlikes = productLikeCacheRepository
.getUnlikesSinceLastSync(lastSyncedTime, currentTime);
// DB에 좋아요 생성 및 삭제
productLikeSynchronizer.sync(newCachedLikes, newCachedUnlikes);
// 상품의 좋아요 카운트 업데이트
productLikeCountSynchronizer.sync(newCachedLikes, newCachedUnlikes);
// 다음 동기화의 시작점으로 설정
productLikeCacheRepository.updateLastSyncTime(currentTime);
}
중요한 포인트:
❌ 나쁜 접근:
배치마다 Redis의 모든 좋아요 데이터를 조회
→ 시간이 지날수록 느려짐
→ 불필요한 데이터 중복 처리
✓ 좋은 접근:
배치마다 "마지막 동기화 시간 이후"의 데이터만 조회
→ 항상 일정한 성능 유지
→ 증분 처리로 효율적
예시:
14:00 - 배치 1차 동기화
처리 데이터: 14:00 ~ 14:05 (좋아요 100건, 취소 30건)
DB 반영 완료
lastSyncTime = 14:05
14:05 - 배치 2차 동기화
처리 데이터: 14:05 ~ 14:10 (좋아요 120건, 취소 25건) ← 새로운 데이터만!
DB 반영 완료
lastSyncTime = 14:10
전체 흐름 요약
시간 흐름으로 보면 이렇습니다:
[사용자 요청 시점]
1. 사용자가 좋아요 클릭
2. Redis에 즉시 저장 (매우 빠름) ✓
3. 응답 반환
└─ 이 시점에서 이미 사용자에게 응답 완료!
[배치 실행 시점 - 매 5분마다]
1. 캐시에서 지난 5분간의 좋아요/취소 데이터 조회
2. 배치 작업으로 DB에 한 번에 저장/삭제
3. 다음 배치 시간 기록
└─ 사용자는 이미 응답을 받았으므로 영향 없음
기존 방식 vs Write-Behind:
기존 방식:
사용자 요청 → DB 읽기 → DB 쓰기 → 응답 반환
Write-Behind:
사용자 요청 → Redis 저장 → 응답 반환 ✓
↓
(배경에서 배치 처리)
Redis → DB (1회당 처리)
결과적으로:
- 응답 속도: 기존의 50배 이상 개선
- DB 부하: 초당 수백 건 쓰기 → 5분마다 1회 대량 처리로 변환
- 사용자 경험: 좋아요 클릭 즉시 반영 (몇 초 지연 무관)
그래서?
캐싱은 성능을 빠르게 하는 기술이 아니라, 데이터 특성을 파악한 선택의 문제입니다.
제가 Cache Aside 테스트를 진행할 때 한 가지 중요한 가정이 있었습니다.
바로 자주 조회되는 상품이 1000개 정도로 특정된다는 점이었습니다.
다시 생각해보니 만약 이 가정이 깨진다면 어떻게 될까요?
예를 들어, 상품 데이터가 100만 건이 있고, 사용자들이 조회하는 상품이 랜덤하게 분산되어 있다면 어떨까요?
그렇다면 캐시 히트율은 급격히 낮아질 것입니다.
캐시에 저장되는 데이터는 1000개인데, 조회되는 상품은 매번 다른 100만 개의 상품 중에서 선택되는 상황이 되는 거죠.
이런 상황에서는 어떤 일이 발생할까요?
- 캐시 미스가 대부분: 대부분의 요청이 캐시에서 찾지 못하고 데이터베이스로 직접 접근
- 캐시 저장의 오버헤드: 캐시에 저장은 되지만 한 번 또는 두 번 조회되고 다시 요청되지 않음
- 메모리 낭비: 캐시 메모리를 차지하지만 실제로는 도움이 되지 않는 데이터들로 가득
- 더 느린 응답: 캐시를 조회하는 시간 + 미스 → 데이터베이스 조회라는 불필요한 오버헤드 발생
결국 캐시를 구현하기 전에 우리가 먼저 해야 할 일은 데이터를 분석하는 것입니다.
- 조회 패턴: 정말로 특정된 데이터들이 자주 조회될까?
- 데이터 규모: 전체 데이터 중 자주 조회되는 데이터는 몇 %일까?
- 캐시 공간: 이 정도 규모의 데이터를 캐시에 보관하는 것이 실제로 가치 있을까?
제 테스트가 성공한 이유는 우연이 아니라 의도적으로 자주 조회되는 1000개의 상품으로 한정했기 때문입니다.
만약 실무에서 캐시를 도입한다면, 단순히 “조회가 많으니까 캐시 쓰자”라기 보다는
“이 데이터는 정말 반복적으로 조회될까? 그렇다면 몇 개 정도일까? 캐시 히트율은 실제로 얼마나 될까?”
이런 질문들에 답하고 난 다음에 도입하는 것이 중요합니다.
캐시는 결국 비즈니스를 파악하고 데이터 특성에 맞게 사용할 때만 진가를 발휘하는 도구라는 걸 느꼈습니다.