
신뢰성이 있다는 건 어떤걸까요?
신뢰성있는 애플리케이션이란 어떤 것일까요? 저는 이 “신뢰성”이라는 말을 다음과 같이 생각했습니다.
“개발자가 의도한대로 동작하는 애플리케이션”
당연히 아무런 장애가 일어나지 않는다면 개발자가 당연하게 의도한대로 구현을 할 것입니다.
제가 여기서 생각하는 것은 “장애상황”에서의 신뢰성을 생각하게 되었습니다.
즉, 장애 상황에서도 개발자가 의도한대로 동작하는 서비스를 생각했습니다.
저는 카프카 애플리케이션이 이 신뢰성을 가지기 위해서 어떻게 설계해야할지 생각한 부분은 정리하려고 합니다.
이벤트 발행
카프카는 Producer를 통해 이벤트를 발행합니다. Producer의 “장애상황”은 어떤게 있을까요?
저는 아래와 같이 정리했습니다.
- 비즈니스로직이 완료되었지만 카프카 브로커로 이벤트를 발행하는데 실패한 상황
- 이벤트를 발행 요청했지만 Ack를 받지 못하는 상황
- 이벤트 발행을 완료했지만 이벤트를 발행한 브로커가 내려간 상황
그럼 위 상황을 고려하기 위해 Producer는 무엇을 할 수 있을까요?
비즈니스와 이벤트 발행의 멱등성
우리가 이커머스 서비스를 운영한다고 생각해볼까요?
우리가 상품을 주문한다고 했을 때 경우에 따라 다를 수 있겠지만 아래와 같은 흐름으로 동작할 것입니다.
- 사용자가 상품을 고르고 주문을 요청
- 주문 상품을 확인하고 결제를 요청
- 결제가 완료된 후 상품 배송 시작
그럼 여기서 크게 도메인을 “주문 / 결제 / 배송”이 될 것입니다.
우리가 MSA 서비스를 운영한다고 하면 이 애그리거트를 기준으로 주문 서비스, 결제 서비스, 배송 서비스가 서로 Kafka를 통해 이벤트를 주고 받으며 위 흐름을 수행합니다.
그럼 위 흐름은 아래와 같이 진행됩니다.
- 주문 API 요청
- 결제 API 요청
- 결제 완료 이벤트 발행
- 배송서비스에서 결제 완료 이벤트 수신
- 배송 시작
여기에서 결제 API에서 결제가 완료됐지만 Kafka의 장애로 인해 이벤트가 발행이 안되는 상황을 가정해볼까요?
아래는 API에서 결제가 완료된 후 Kafka로 이벤트를 발행하는 코드입니다.
@Transactional
public Payment pay(PaymentCommand command) {
// 결제 비즈니스 수행
// 이벤트 발행
producer.publish(PaymentCompletedEvent);
return savedPayment;
}
여기서 Kafka가 장애가 발생하면 어떻게 될까? 라는 고민을 해보면 문제가 도드라집니다.
첫번째, 이벤트 발행 실패로인해 우리의 비즈니스가 모두 롤백이 되어버립니다.
두번째, 사용자 입장에서는 API로부터 200응답을 받지 않아 장애 상황으로 인식되어버립니다.
그럼 이 문제를 어떻게 해결할 수 있을까요?
간단하게 생각해보면 pay() 안에서 이벤트를 발행을 안하도록하면 됩니다.
그럼 이벤트 발행은 어떻게 진행하면 될까요?
Transactional Outbox Pattern
MSA에서는 이 문제를 Transactional Outbox패턴으로 해결할 수 있다고 정의합니다.
Transactional Outbox 패턴은 microservices.io에서 아래와 같이 정의합니다.
아래는 위 문서의 내용을 제가 번역한 내용입니다.
Problem
- 어떻게 데이터베이스 업데이트와 메세지 브로커로의 메세지 전송을 원자적으로 할 수 있을까요?
Solution
- 해결책은 메시지를 보내는 서비스가 먼저 비즈니스 엔티티를 업데이트하는 트랜잭션의 일부로 메시지를 데이터베이스에 저장하는 것입니다. 그런 다음 별도의 프로세스가 메시지를 메시지 브로커로 보냅니다.
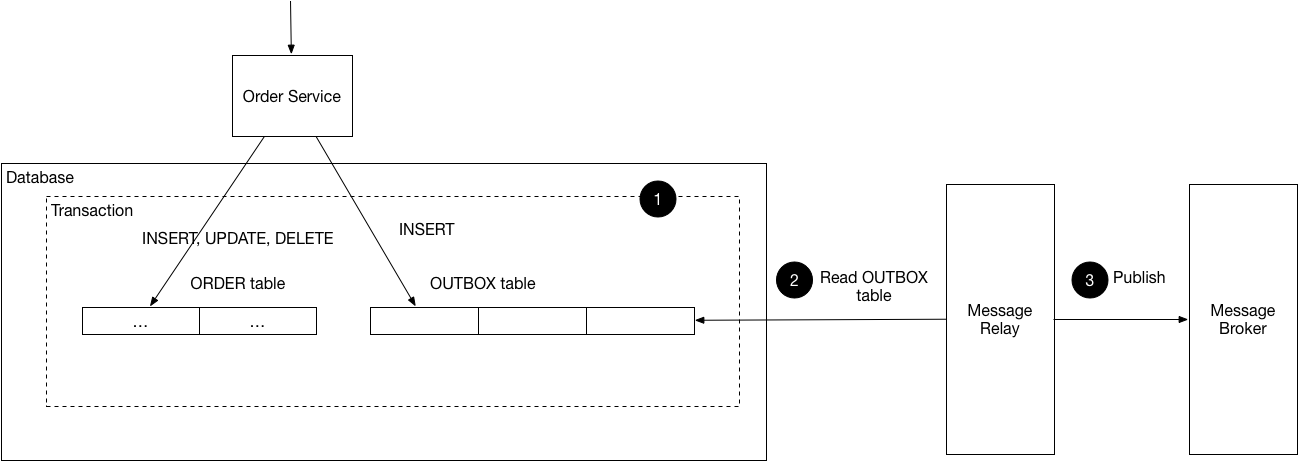
이 패턴에 참여하는 사람들은 다음과 같습니다.
- Sender - 메시지를 보내는 서비스
- Database - 비즈니스 엔티티와 메시지 발신함을 저장하는 데이터베이스
- Outbox - 관계형 데이터베이스인 경우, 이는 보낼 메시지를 저장하는 테이블입니다. NoSQL 데이터베이스인 경우, 발신함은 각 데이터베이스 레코드(예: 문서 또는 항목)의 속성입니다.
- Message Relay - 발신함에 저장된 메시지를 메시지 브로커로 전송합니다.
즉, 결제를 수행을 완료하고 이벤트를 바로 발행하는 것이 아닌 Outbox 테이블에 먼저 저장을 한 후, 별도의 시스템을 통해 이벤트를 발행하도록 하면 됩니다.
저는 Outbox 테이블을 아래와 같이 구성했습니다.
public class EventOutbox {
private final EventOutboxId id;
private final EventId eventId;
private final AggregateType aggregateType;
private final AggregateId aggregateId;
private final EventType eventType;
private final EventOutboxStatus status;
private final EventPayload payload;
private final PublishedAt publishedAt;
private final CreatedAt createdAt;
private final UpdatedAt updatedAt;
}
각 필드는 다음과 같은 값을 의미합니다.
- EventOutboxId : Outbox의 데이터베이스 ID
- EventId : 이벤트의 고유 식별자
- AggregateType : 애그리거트의 유형 (결제, 상품, 주문, 배송 …)
- AggregateId : 애그리거트의 식별자 (결제 ID, 상품 ID …)
- EventType : 발생한 이벤트의 종류 (결제 완료, 상품 배송 시작, 주문 완료 …)
- EventOutboxStatus : 이벤트 발행 상태 (발행 대기/완료/실패)
- EventPayload : 이벤트 발행시 전달할 값
- PublishedAt : 이벤트 발행 시간
- CreatedAt : Outbox 생성 시간
- UpdatedAt : Outbox 마지막 수정 시간
그리고 결제 서비스에서 직접 이벤트를 발행하는 대신 Outbox를 저장합니다.
@Transactional
public Payment pay(PaymentCommand command) {
// 결제 비즈니스 수행
// 이벤트 발행
outboxRepository.save(EventOutbox);
return savedPayment;
}
이제 별도의 스케줄러를 통해 이벤트를 발행합니다.
@Transactional
@Scheduled(fixedDelay = 1000)
public void publish() {
// 발행 대상 조회
List<EventOutbox> outboxes = eventOutboxRepository.findAllBy(
AggregateType.PAYMENT,
EventType.PAYMENT_COMPLETED,
EventOutboxStatus.PENDING
);
// 이벤트 발행
outboxes.stream()
.map(EventOutbox::getPayload)
.map(payload -> JacksonUtil.convertToObject(payload.value(), PaymentCompletedEvent.class))
.forEach(publisher::publish);
// outbox 상태 업데이트
outboxes.stream()
.map(EventOutbox::publish)
.forEach(eventOutboxRepository::save);
}
이제 Kafka에 장애가 발생하더라도 사용자는 API를 통해 정상 응답을 받고 별도 스케줄러에만 장애가 발생합니다.
이 장애 동안은 Outbox 테이블의 상태가 대기상태(PENDING)에서 변하지 않기 때문에 Kafka가 복구된 이후에 자동으로 발행되게 됩니다.
Idempotent Producer
프로듀서에서 발생할 수 있는 장애 상황 중 또 하나는 이벤트를 발행하고나서 Ack를 받지 못하는 상황입니다.
흐름은 아래와 같습니다.
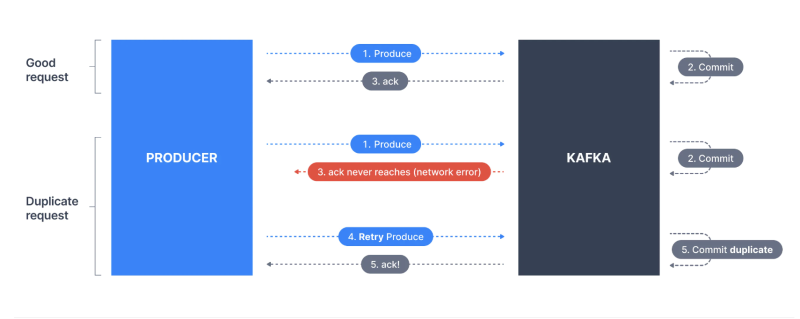
- Producer가 카프카로 이벤트를 발행합니다.
- 카프카가 Producer에게 이벤트 수신확인 (Ack)를 전달한다.
- Ack가 Producer에게 전달되지 못한다.
- Producer는 Ack를 받지 못해 이벤트 발행을 재시도하게 된다.
- Producer는 Ack를 받게 된다.
- 카프카는 이벤트를 중복 저장하게 된다.
위 흐름으로 카프카는 멱등 프로듀서(Idempotent Producer)를 제공합니다.
멱등 프로듀서는 아래와 같은 흐름으로 이벤트의 중복 저장을 막습니다.
- 고유 식별자 부여 (PID & Sequence Number):
- 프로듀서가 카프카에 연결되면 고유한 PID를 할당받습니다.
- 보내는 각 메시지 배치(batch)에는 Sequence Number가 부여됩니다.
- 브로커의 중복 검사:
- 브로커는 파티션별로 해당 프로듀서의 마지막으로 받은 시퀀스 번호를 기록하고 있습니다.
- 프로듀서가 같은 PID와 시퀀스 번호를 가진 메시지를 다시 보내면, 브로커는 이를 중복으로 간주하고 저장하지 않습니다.
Spring Boot 3.X 부터는 기본적으로 별도의 설정이 없더라도 멱등성 프로듀서가 설정이 됩니다.
ISR (In-Sync Replicas)
Kafka에서는 클러스터가 장애상황이라도 안정성과 가용성을 보장합니다.
이벤트 발행은 카프카의 파티션에 적재가 됩니다.
그럼 이벤트 발행이 완료됐지만 완료된 브로커에 문제가 생기면 어떻게 될까요?
파티션에 적재된 이벤트들은 무시될까요?
여기서 카프카는 안정성과 가용성을 보장하기위해 ISR(In-Sync Replicas)을 지원합니다.
In-Sync Replicas라는 의미가 무엇일까요? 말 그대로 복제본들을 동기화시킨다는 의미입니다.
ISR에는 Leader Partition과 Leader 파티션을 동기화하고있는 Follower Partition의 개념이 존재합니다.
ISR은 아래와 같이 동작합니다.
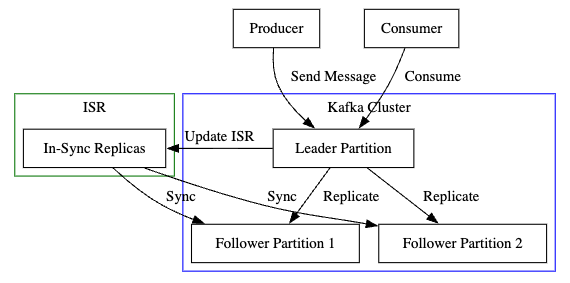
- Producer: 메시지를 생성하여 Leader Partition에 전달한다.
- Leader Partition: 메시지를 받아 저장하고, ISR에 있는 Follower Partition들에게 복제한다.
- Follower Partitions: Leader Partition으로부터 메시지를 복제받는다.
- Consumer: Leader Partition에서 메시지를 소비한다.
위와 같은 구조로 Leader Partition이 내려가더라도 Follower Partition을 통해 안정성을 보장합니다.
여기서 이 Leader Partition과 Follower Partition의 수는 RF(Replication Factor)라는 설정 값을 통해 설정됩니다. RF가 3이면 하나의 Leader Partition과 두 개의 Follower Partition이 생성됩니다.
그리고 각각의 파티션은 아래 이미지와 같이 다른 브로커에 할당이 됩니다.
때문에 RF의 수가 브로커의 수보다 작다면 에러가 발생하게 됩니다.
Error: replication factor: 3 larger than available brokers: 2
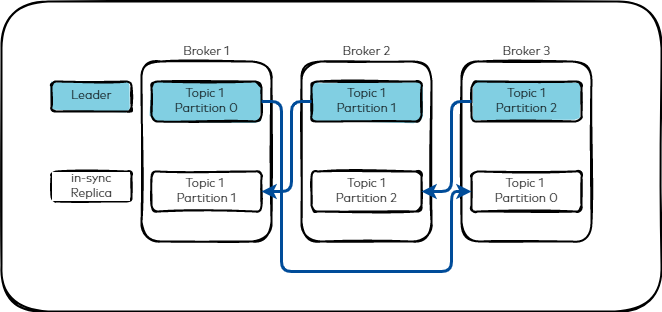
Kafka Document 에서는 일반적인 경우 RF를 3으로 설정한다고합니다.
Acks
여기서 Producer는 acks 설정을 할 수 있습니다.
acks는 Producer가 “이벤트 발행을 완료했다”라는 응답을 어떻게 받을 것이지에 대한 설정값입니다.
- acks=0 : Producer가 자신이 보낸 이벤트에 대해 카프카의 확인을 기다리지 않습니다.
- acks=1 : Producer가 Leader Partition이 이벤트를 잘 받았는지를 기다립니다. Follower Partition들은 기다리지 않습니다.
- acks=all : Producer가 Leader, Follower Partition 모두 이벤트를 잘 받았는지를 기다립니다.
당연하게도 acks 0에서 1, all로 갈 수록 이벤트 전송 속도는 감소합니다.
대신에 트레이드 오프로 이벤트 손실률 또한 감소하게 됩니다.
신뢰성 있는 애플리케이션 운영을 위해서는 acks=all로 설정하는게 적절해보입니다.
이벤트 소비
카프카는 Consumer를 통해 이벤트를 소비합니다. Consumer에서는 어떤 장애상황이 있을 수 있을까요?
- 이벤트를 여러번 중복 처리하여 중복된 데이터가 적재되는 상황
- 이벤트를 받아서 처리했지만 Kafka에서 커밋이 되지 않은 상황
- 아직 비즈니스가 처리되지 않았지만 Kafka에 이미 오프셋을 커밋한 상황
위 상황을 고려하기 위해서 Consumer는 어떤 것을 할 수 있을까요?
Transactional Inbox
이벤트 발행에는 Transactional Outbox 패턴이 있었다면 이벤트 소비에는 Transactional Inbox 패턴이 있습니다.
Outbox는 “발송함”의 의미로 이벤트를 발행하기 전에 담아놓는 역할을 했습니다.
Inbox는 반대로 “수신함”의 의미로 받은 이벤트를 담아놓는 역할을 합니다.
그럼 이미 받은 이벤트는 왜 담아서 저장해놓을까요?
그 의의는 “이벤트를 여러번 중복 처리하여 중복된 데이터가 적재되는 상황”에 있습니다.
이벤트를 담아두어 중복된 이벤트가 소비되는 경우에도 1번만 소비한 것 처럼(exactly-once) 멱등하게 유지하기 위함입니다.
위에서 Outbox의 예시의 연장선으로 결제가 완료되어 배송 서비스에서 결제 이벤트를 수신한다고 가정합시다.
저는 Inbox를 아래와 같이 구성했습니다.
public class EventInbox {
private final EventInboxId id;
private final EventId eventId;
private final AggregateType aggregateType;
private final AggregateId aggregateId;
private final EventType eventType;
private final EventInboxStatus status;
private final EventPayload payload;
private final CreatedAt createdAt;
private final UpdatedAt updatedAt;
}
각 필드는 다음과 같은 값을 의미합니다.
- EventInboxId : Inbox의 데이터베이스 ID
- EventId : 이벤트의 고유 식별자
- AggregateType : 애그리거트의 유형 (결제, 상품, 주문, 배송 …)
- AggregateId : 애그리거트의 식별자 (결제 ID, 상품 ID …)
- EventType : 발생한 이벤트의 종류 (결제 완료, 상품 배송 시작, 주문 완료 …)
- EventOutboxStatus : 이벤트 발행 상태 (처리 대기/완료/실패)
- EventPayload : 이벤트 발행시 전달할 값
- CreatedAt : Outbox 생성 시간
- UpdatedAt : Outbox 마지막 수정 시간
Outbox와 매우 유사해보입니다. 하지만 다른 점이 있습니다.
Outbox는 “발행” 관점의 이벤트를 적었지만 Inbox는 “수신” 기준의 이벤트 유형을 적습니다.
예를 들어, Outbox가 “결제 완료” 라면 Inbox는 “배송 시작“에 대한 이벤트 유형을 적도록 했습니다.
이렇게 Consumer는 어디에서 이벤트가 발행됐는지는 알 필요가 없고 어떤 처리를 해야할 지만 관심있으면 된다고 판단했기 때문입니다.
그리고 Consumer가 하나의 토픽이 아닌 여러 토픽에서 발행되는 이벤트를 처리해야된다라고 할 때 (예를 들어, 알림 전송) 애매한 상황이 발생할 수 있습니다.
이제 저장된 Inbox를 어떻게 활용하면 좋을까요? 저는 아래와 같이 구현해봤습니다.
- 이벤트를 소비하기전 EventId를 통해 Inbox에 이미 소비가된 이벤트인지 확인한다.
- 소비가 된적이 없다면 비즈니스를 처리한다.
- 처리 완료 후 Inbox를 저장한다.
- 처리중 에러가 발생하면 Inbox에 실패 상태로 저장한다.
이를 코드로 구현하면 아래와 같습니다.
// 중복 확인: eventId로 이미 처리된 이벤트인지 확인
if (eventInboxRepository.findByEventId(eventId).isPresent()) {
log.info("이미 처리된 이벤트입니다. eventId={}, eventType={}", eventId.value(), eventType.name());
return null;
}
try {
// 비즈니스 로직처리
deliveryService.start();
// Inbox에 저장
EventInbox eventInbox = EventInbox.create(
eventId,
aggregateType,
new AggregateId(aggregateId),
eventType,
new EventPayload(payloadJson)
);
eventInboxRepository.save(eventInbox.process());
log.info("이벤트가 정상 처리되었습니다. eventId={}, eventType={}", eventIdValue, eventType);
return result;
} catch (Exception exception) {
// 처리 실패 시 FAILED 상태로 저장
EventInbox failedInbox = EventInbox.create(
eventId,
aggregateType,
new AggregateId(aggregateId),
eventType,
new EventPayload(payloadJson)
);
eventInboxRepository.save(failedInbox.fail());
log.error("이벤트 처리 중 오류가 발생했습니다. eventId={}, eventType={}", eventIdValue, eventType, exception);
throw exception;
}
하지만 이 처리를 Consumer에서 비즈니스 로직을 처리하기전에 매번 구현하는 것은 매우 번거로운 일입니다.
저는 그래서 AOP를 이용해 애노테이션으로 위 로직을 실행하도록 했습니다.
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface InboxEvent {
String aggregateType();
String eventType();
String eventIdField();
String aggregateIdField() default "id";
}
@InboxEvent(
aggregateType = "DELIVERY",
eventType = "DELIVERY_START",
eventIdField = "eventId",
aggregateIdField = "orderId"
)
public void delivery() {
// 비즈니스 로직 처리
}
이를 통해 이벤트를 멱등하게 처리할 수 있습니다.
auto commit
만약에 Consumer에서 비즈니스의 처리가 완료가 안됐는데 Kafka의 오프셋을 커밋해버리면 어떻게 될까요?
그럼 아래와 같은 문제가 발생할 수 있습니다.
- Consumer에서 100개의 이벤트를 polling 하여 처리 중
- 40개 정도 처리됐을 때, 100개 이벤트의 offset이 commit
- 50개 정도 처리됐을 때 오류 발생
- 처리가 안된 50개의 이벤트는 유실
Kafka에서는 enable.auto.commit과 auto.commit.interval.ms 라는 옵션으로 이벤트를 자동으로 커밋을 할껀지, 어떤 주기로 자동으로 커밋을 할 껀지 설정할 수 있습니다.
하지만 enable.auto.commit=true 로 주게 된다면 위와 같은 문제가 발생할 수 있습니다.
때문에 자동으로 커밋을 하는게 아닌 우리가 원하는 시점에 오프셋을 커밋하는게 중요합니다.
그럼 저 설정만 false로 두면 괜찮을까요? 아닙니다.
사실 Spring은 기본적으로 오프셋 커밋을 활성화 상태로 두고 있기 때문에 오프셋이 자동으로 커밋이 되게 됩니다.
그래서 수동으로 커밋을 처리하기위해 AckMode를 수정해야합니다.
AckMode는 아래와 같이 있습니다.
- RECORD : 레코드 단위로 프로세싱 이후 커밋
- BATCH : poll() 메서드로 호출된 레코드가 모두 처리된 이후 커밋, 스프링 카프카 컨슈머의 AckMode 기본값
- TIME : 특정 시간 이후에 커밋
- COUNT : 특정 개수만큼 레코드가 처리된 이후 커밋
- COUNT_TIME : TIME, COUNT 옵션 중 맞는 조건이 하나라도 나올 경우 커밋
- MANUAL : Acknowledgement.acknowledge() 메서드가 호출되면 다음번 poll() 때 커밋을 한다.
- MANUAL_IMMEDIATE : Acknowledgement.acknowledge() 메서드를 호출한 즉시 커밋한다.
우리가 비즈니스가 모두 완료되고 커밋을 수행한다. 라고 했을 때는 MANULAL 옵션을 사용하여 수동으로 커밋을 하는게 안정적이라고 생각했습니다.
다른 어떤 방법이 있을까?
Producer에서의 문제상황과 Consumer 입장에서의 문제 상황을 고민을 하면서 다른 방식은 없을까? 고민을 많이 하게 되었습니다.
Transanctional Outbox 패턴이나 Inbox 패턴 모두 문제 상황을 극복하기 위해 좋은 선택지 일 수 있습니다.
하지만 그만큼 Outbox 테이블과 Inbox 테이블을 관리해야되는 관리 포인트가 생기고, 스케줄러를 통해 이벤트를 발행했을 때 관리해야하는 포인트 또한 늘어날 수 있을 것 같다라는 생각이들었습니다.
AckMode또한 어차피 poll()한 이벤트가 모두 완료되는 경우에만 오프셋이 커밋되야한다면 그냥 MANUAL이 아닌 BATCH를 사용하는건 어떨까? 오히려 직접 코드를 통해 커밋을 안해도 되니까 누군가 코드를 수정해서 생길 수 있는 문제를 방지할 수 있지 않을까? 라는 고민도 하게 됐습니다.
카프카는 높은 안정성과 고가용성을 보장하는 만큼 보장하기위해 많은 옵션들과 구성요소들이 있습니다.
우리가 3000만원짜리 DSLR 카메라를 산다고 했을 때, 이 카메라에서는 좋은 사진을 찍기 위해 많은 옵션들을 제공하지만 활용할 줄 모른다면 저렴한 카메라와 다를게 없는 것 처럼 카프카 또한 마찬가지라고 생각했습니다.
카프카를 충분히 이해하고 활용해야 안정적이고 고가용성을 보장하는 서비스를 운영할 수 있겠다고 생각하게 되었습니다.