
개요
실시간 표절검사 시스템
카피킬러 표절검사 과정 중에는 후보군 추출이라는 프로세스가 존재합니다. 후보군 추출은 사내 문서들을 탐색하는 검색엔진을 통해 진행됩니다.
검색엔진은 검색 범위에 따라 프로필별로 나누어져 있으며, 프로필의 종류는 아래 5가지입니다:
- BLACK_HOLE
- COC
- UNION
- GROUP
- DOMAIN
처음에는 작은 트래픽을 제어하기 위해 동기 방식으로 충분했습니다. 하지만 비즈니스가 성장하면서 요청이 급증했고, 비동기 처리로 변경하게 되었습니다. 이제 Kafka의 Consumer를 통해 이벤트를 받아 처리하고 있습니다.
하지만 새로운 문제가 생겼습니다.
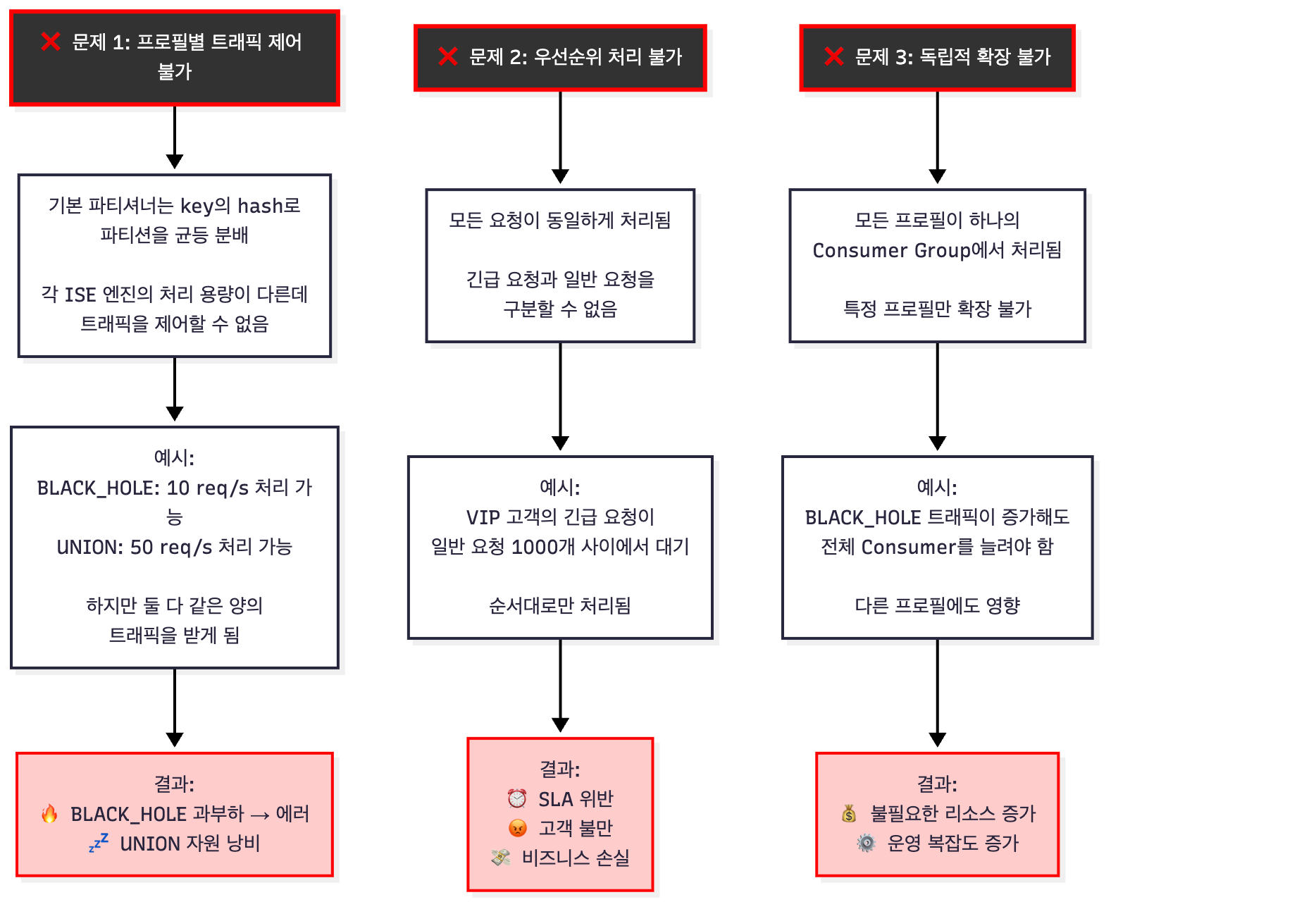
마주친 문제
검색엔진이 받을 수 있는 부하는 Worker 수에 따라 한정되어 있습니다. 이 과정에서 두 가지 복잡한 요구사항이 생겼습니다:
요구사항 1: 프로필별 트래픽 제어
검색엔진은 프로필별로 다른 데이터 규모와 복잡도를 가지고 있습니다.
- BLACK_HOLE: 가장 많은 데이터, 검색이 빠름 → 높은 처리량 수용 가능
- DOMAIN: 적은 데이터, 검색이 복잡함 → 낮은 처리량만 수용 가능
따라서 각 프로필의 처리 능력에 맞게 프로필별로 독립적으로 부하를 제어해야 했습니다.
요구사항 2: 우선순위 기반 처리
검색엔진의 속도가 요청 속도를 따라가지 못할 때, 요청들이 대기 큐에 쌓입니다. 이때:
- 일반 요청(LOW)은 오래 기다려도 괜찮음
- 긴급 요청(HIGH)은 즉시 처리되어야 함
하지만 모든 요청이 같은 대기열에 있으면, 아무리 긴급한 요청이라도 앞의 일반 요청들을 기다려야 합니다.
현재 요구사항을 만족해야 하는 문제 상황을 도식화하면 아래와 같습니다:
솔루션 탐색: 왜 Custom Partitioner를 선택했는가?
처음엔 여러 해결책을 고민했습니다:
- 토픽을 나누기: 프로필별로 다른 Kafka 토픽 사용
- 장점: 구현이 간단함
- 단점: 토픽 개수가 기하급수적으로 증가 (프로필 5개 × 우선순위 3개 = 15개 토픽)
- 컨슈머 그룹 분리: 프로필별로 다른 컨슈머 그룹 사용
- 장점: 프로필별 독립적 처리
- 단점: 우선순위 처리가 불가능
- 파티션 분리 (Custom Partitioner 사용): ✅ 최종 선택
- 장점: 하나의 토픽으로 프로필과 우선순위를 모두 제어
- 단점: 파티셔너 로직 구현 필요
결론적으로, 하나의 토픽에서 파티션을 논리적으로 분리하는 것이 가장 깔끔했습니다.
Spring Kafka 파티셔너 이해하기
파티셔너란?
Spring Kafka의 파티셔너는 메시지를 어떤 파티션으로 보낼지 결정하는 컴포넌트입니다.
생각해보면 간단합니다:
- Kafka 토픽은 여러 파티션으로 구성됨
- 메시지가 들어오면 파티셔너가 “이 메시지는 몇 번 파티션으로 갈까?” 를 판단
- 각 파티션은 독립적으로 처리되므로, 파티션 분배가 곧 부하 분배
파티셔너의 핵심 개념
파티션 분배 전략
- 파티셔너는 메시지의 **키(key)를 기반으로 파티션을 결정합니다
- 같은 키를 가진 메시지는 항상 같은 파티션으로 전송되어 순서가 보장됩니다
기본 파티셔너의 동작
- Spring Kafka는 기본적으로
DefaultPartitioner를 사용합니다 - 키가 있으면: 해시값을 이용해 파티션 선택
- 키가 없으면: 라운드 로빈 방식으로 분배
우리가 할 수 있는 커스텀
Partitioner인터페이스를 구현하여 원하는 분배 전략 적용 가능- Key 값을 우리가 설계한 대로 파싱하여 어떤 파티션으로 갈지 결정
파티셔닝 흐름
프로듀서가 메시지를 전송하면 파티셔너가 메시지의 키와 값, 토픽 정보를 받아 파티션 번호를 반환합니다. 이후 해당 파티션으로 메시지가 전송되고, 컨슈머는 할당된 파티션에서 메시지를 읽어옵니다.

- Producer에서 4개의 메시지 생성 (일부는 키 있음, 일부는 키 없음)
- Partitioner가 각 메시지를 분석
- 키가 있으면 해시 계산으로 파티션 결정
- 키가 없으면 라운드 로빈으로 분배
- 결정된 Partition으로 메시지 전송
- 각 Consumer가 할당된 파티션에서 메시지 소비
같은 키(user-A)를 가진 메시지는 항상 같은 파티션(Partition 1)으로 가는 것을 확인할 수 있습니다.
커스텀 파티셔너 설계: 핵심 아이디어
파티션은 처리의 단위다
여기서 핵심 통찰이 있습니다:
“파티션 = 독립적인 처리 라인”
- 각 파티션은 완전히 독립적으로 처리됨
- 파티션 A의 작업이 느려도 파티션 B에는 영향 없음
- 따라서 파티션이 많을수록 병렬 처리 가능 → 전체 처리량 증가
예시:
- 파티션 1개 → 컨슈머 1개만 활용 가능 → 초당 1만 메시지 처리
- 파티션 10개 → 컨슈머 10개 활용 가능 → 초당 10만 메시지 처리
이 아이디어를 우리 문제에 적용하면 어떻게 될까?
설계: 파티션으로 책임을 나눈다
1단계: 프로필별 파티션 분리
문제: 각 검색엔진의 처리 능력이 다르다
첫 번째 아이디어: 프로필별로 다른 수의 파티션을 할당
- BLACK_HOLE (처리 능력 높음): 10개 파티션 할당 → 컨슈머 10개 동시 처리
- DOMAIN (처리 능력 낮음): 2개 파티션 할당 → 컨슈머 2개만 처리
예시: 전체 파티션 수가 50개일 때의 분배
BLACK_HOLE: 0~9 (10개)
COC: 10~19 (10개)
UNION: 20~29 (10개)
GROUP: 30~39 (10개)
DOMAIN: 40~49 (10개)
2단계: 우선순위별 파티션 분리
문제: 같은 프로필 내에서 긴급 요청이 일반 요청에 밀린다
두 번째 아이디어: 프로필 내부에서 다시 파티션을 우선순위별로 분리
우선순위는 세 단계:
- LOW: 일반적인 표절검사 요청
- MIDDLE: 조금 더 빠른 처리가 필요한 요청
- HIGH: 긴급하게 처리되어야 하는 요청
예시: BLACK_HOLE 프로필 (0~9) 내부 분배
0~5: LOW 요청 처리 (6개 파티션)
6~8: MIDDLE 요청 처리 (3개 파티션)
9: HIGH 요청 처리 (1개 파티션)
왜 이렇게 설계했는가?
이렇게 하면:
- 프로필별 독립적 부하 제어: 각 검색엔진의 능력에 맞게 파티션 할당
- 우선순위 대기시간 최소화: HIGH 우청이 비어있으면 즉시 처리, LOW 요청이 대기 중이어도 무방
- 유연한 확장: 파티션 수를 설정 파일로 관리하여 동적 조정 가능
실제 효과를 생각해보면
시나리오: LOW 파티션에 요청이 1000개 대기 중, HIGH 파티션은 비어있음
- 일반적인 큐: HIGH 요청이 1000개 대기 후 처리 (X)
- 우리 설계: HIGH 파티션이 비어있으면 즉시 처리 (O)
구현
Partitioner 인터페이스
Kafka의 파티션을 분리했으면, 이제 이벤트 발행 시 프로필과 우선순위에 맞는 파티션으로 이벤트가 전송되도록 Custom Partitioner를 구현해야 합니다.
Custom Partitioner는 Partitioner 인터페이스를 구현하여 만듭니다:
public interface Partitioner extends Configurable, Closeable {
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
void close();
default void onNewBatch(String topic, Cluster cluster, int prevPartition) {
}
}
여기서 partition() 메서드의 반환값인 int는 메시지가 전송될 파티션 번호를 의미합니다.
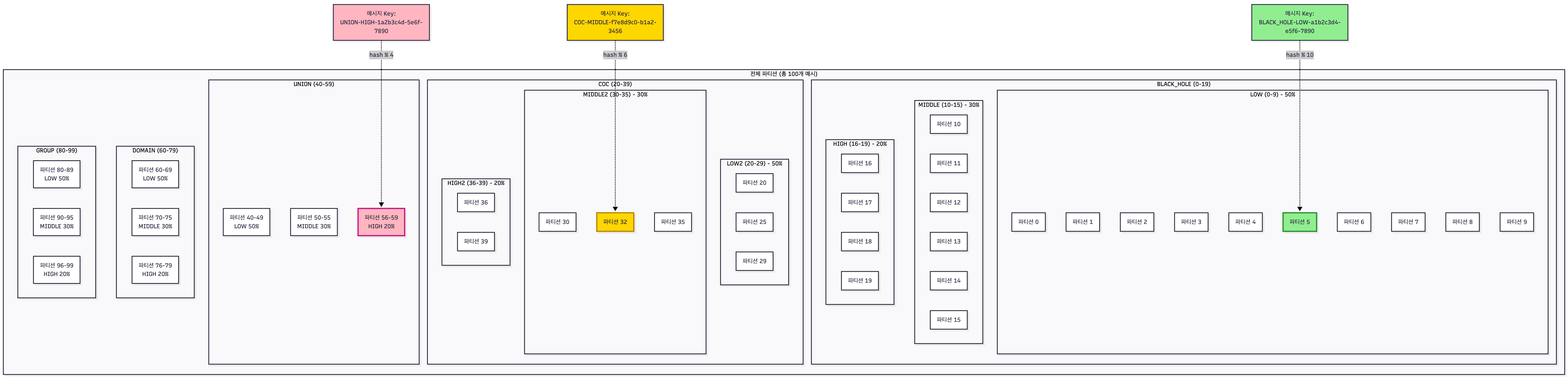
Key 설계
파티셔너는 이벤트의 Key 값을 통해 어떤 파티션으로 갈지 결정합니다.
이를 위해 Key를 다음과 같은 형식으로 정의했습니다:
형식: {프로필}-{우선순위}-{UUID}
예시: BLACK_HOLE-HIGH-550e8400-e29b-41d4-a716-446655440000
- 프로필: 어떤 검색엔진 그룹으로 갈지 결정
- 우선순위: 해당 프로필 내에서 어떤 우선순위 파티션으로 갈지 결정
- UUID: 같은 프로필과 우선순위 내에서 파티션을 균등하게 분산
1. 설정 클래스 정의
먼저 각 프로필별 파티션 수와 우선순위별 비율을 설정할 수 있는 구조를 정의했습니다.
@ConfigurationProperties(prefix = "kafka.partitioning")
public record PartitioningConfig(
Map<ProfileType, ProfilePartitioningConfig> profiles
) {
}
- profiles: 프로필 타입별로 파티션 설정을 관리하는 Map
@ConfigurationProperties를 통해 application.yml에서 설정값을 주입받습니다.
public record ProfilePartitioningConfig(
int partitionCount,
PriorityRatioConfig priorityRatio
) {
}
- partitionCount: 해당 프로필에 할당할 파티션 개수
- priorityRatio: LOW, MIDDLE, HIGH 우선순위별 파티션 비율 설정
public record PriorityRatioConfig(
int low,
int middle,
int high
) {
public int getTotalRatio() {
return low + middle + high;
}
}
- low, middle, high: 각 우선순위별 비율 (예: 6:3:1)
- getTotalRatio(): 전체 비율의 합을 계산하여 파티션 분배 시 사용
2. CustomPartitioner 구현
Kafka의 Partitioner 인터페이스를 구현하여 커스텀 파티셔닝 로직을 작성했습니다.
@Slf4j
public class CustomPartitioner implements Partitioner {
private PartitioningConfig partitioningConfig;
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
int totalPartitions = cluster.partitionCountForTopic(topic);
// 1. Key 검증
KeyValidator.validate(key);
String keyString = key.toString();
// 2. Key에서 프로필과 우선순위 추출
ProfileType profileType = ProfileKeyExtractor.extractProfileType(keyString);
Priority priority = ProfileKeyExtractor.extractPriority(keyString);
// 3. 프로필에 해당하는 설정 조회
ProfilePartitioningConfig config = partitioningConfig.profiles().get(profileType);
// 4. 설정된 파티션 수와 실제 토픽의 파티션 수 검증
int configuredPartitions = config.partitionCount();
int profilePartitions = configuredPartitions;
if (configuredPartitions > totalPartitions) {
log.warn(MessageLogFactory.createFrom(
configuredPartitions,
profileType,
totalPartitions,
"Configured partitions exceeds total partitions"
).toJsonString());
profilePartitions = totalPartitions;
}
// 5. 프로필의 시작 오프셋 계산
int profileStartOffset = PartitionOffsetCalculator.calculateOffset(
profileType, partitioningConfig, totalPartitions
);
// 6. 우선순위에 따른 최종 파티션 계산
return PriorityPartitionCalculator.calculatePartition(
priority,
config.priorityRatio(),
profilePartitions,
profileStartOffset,
keyString
);
}
@Override
public void configure(Map<String, ?> configs) {
Object partitioningConfigObj = configs.get("partitioning.config");
if (partitioningConfigObj instanceof PartitioningConfig config) {
this.partitioningConfig = config;
} else {
log.error(ErrorLogFactory.createFrom(
"PartitioningConfig not found in configuration"
).toJsonString());
throw new IllegalStateException("PartitioningConfig is required for CustomPartitioner");
}
}
@Override
public void close() {
// 리소스 정리가 필요할 때 구현
}
}
주요 동작 흐름:
- Key 검증:
KeyValidator를 통해 Key의 유효성 검증 (null 체크 및 형식 검증) - Key 파싱:
{프로필}-{우선순위}-{UUID}형식에서 프로필과 우선순위 추출 - 프로필 설정 조회: 해당 프로필의 파티션 설정 가져오기
- 파티션 수 검증: 설정된 파티션 수가 실제 토픽의 파티션 수를 초과하는지 검증
- 오프셋 계산: 이전 프로필들의 파티션 개수를 합산하여 시작 위치 계산
- 최종 파티션 결정: 우선순위별 비율에 따라 상대 파티션 계산 후 오프셋 더하기
3. Key 추출 유틸리티
Key 문자열에서 프로필과 우선순위를 추출하는 유틸리티 클래스입니다.
public final class ProfileKeyExtractor {
public static ProfileType extractProfileType(String key) {
return extractKeyPart(key, 0)
.map(ProfileKeyExtractor::parseProfileType)
.orElse(ProfileType.BLACK_HOLE);
}
public static Priority extractPriority(String key) {
return extractKeyPart(key, 1)
.map(Priority::from)
.orElseThrow(() -> new IllegalArgumentException("Invalid priority in key: " + key));
}
private static Optional<String> extractKeyPart(String key, int index) {
if (Objects.isNull(key)) {
return Optional.empty();
}
String[] parts = key.split("-");
if (parts.length <= index) {
return Optional.empty();
}
return Optional.of(parts[index]);
}
}
동작 방식:
- Key를
-로 분리하여 각 부분을 추출 - 0번 인덱스: 프로필 타입 (예: BLACK_HOLE, COC)
- 1번 인덱스: 우선순위 (예: LOW, MIDDLE, HIGH)
- 파싱 실패 시 기본값(BLACK_HOLE) 반환 또는 예외 발생
4. 파티션 오프셋 계산
각 프로필의 시작 파티션 번호를 계산하는 유틸리티입니다.
public final class PartitionOffsetCalculator {
public static int calculateOffset(ProfileType targetProfile,
PartitioningConfig config,
int totalPartitions) {
return Arrays.stream(ProfileType.values())
.takeWhile(profile -> profile != targetProfile)
.mapToInt(profile -> getProfilePartitionCount(profile, config, totalPartitions))
.sum();
}
private static int getProfilePartitionCount(ProfileType profile,
PartitioningConfig config,
int totalPartitions) {
return config.profiles()
.entrySet()
.stream()
.filter(entry -> entry.getKey() == profile)
.findFirst()
.map(entry -> calculateValidPartitionCount(entry.getValue(), totalPartitions))
.orElse(0);
}
}
계산 로직:
ProfileTypeenum의 순서대로 순회- 목표 프로필 이전까지의 모든 프로필의 파티션 개수를 합산
예시:
BLACK_HOLE: 10개 (파티션 0~9)
COC: 10개 (파티션 10~19)
UNION: 10개 (파티션 20~29) ← 오프셋 = 10 + 10 = 20
UNION 프로필의 시작 오프셋은 이전 프로필들(BLACK_HOLE, COC)의 파티션 수를 합산한 20입니다.
5. 우선순위별 파티션 계산
프로필 내에서 우선순위에 따라 상대적인 파티션 번호를 계산합니다.
public final class PriorityPartitionCalculator {
public static int calculatePartition(
Priority priority,
PriorityRatioConfig ratioConfig,
int profilePartitions,
int profileStartOffset,
String key
) {
var partitionDistribution = calculatePartitionDistribution(ratioConfig, profilePartitions);
int relativePartition = calculateRelativePartition(priority, partitionDistribution, key);
return profileStartOffset + relativePartition;
}
private static PartitionDistribution calculatePartitionDistribution(
PriorityRatioConfig ratioConfig,
int totalPartitions
) {
int totalRatio = ratioConfig.getTotalRatio();
int lowPartitions = (ratioConfig.low() * totalPartitions) / totalRatio;
int middlePartitions = (ratioConfig.middle() * totalPartitions) / totalRatio;
int highPartitions = totalPartitions - lowPartitions - middlePartitions;
return new PartitionDistribution(
Math.max(1, lowPartitions),
Math.max(1, middlePartitions),
Math.max(1, highPartitions)
);
}
private static int calculateRelativePartition(
Priority priority,
PartitionDistribution distribution,
String key
) {
int hashCode = Math.abs(Objects.hashCode(key));
return switch (priority) {
case LOW -> hashCode % distribution.low();
case MIDDLE -> distribution.low() + (hashCode % distribution.middle());
case HIGH -> distribution.low() + distribution.middle() + (hashCode % distribution.high());
};
}
private record PartitionDistribution(int low, int middle, int high) {
}
}
계산 과정:
- 우선순위별 파티션 분배
- 비율 설정(예: 6:3:1)에 따라 파티션 개수 계산
- 최소 1개의 파티션은 보장
- 상대 파티션 번호 계산
- Key의 해시값을 이용하여 같은 우선순위 내에서 분산
- LOW: 0번부터 시작
- MIDDLE: LOW 파티션 개수만큼 오프셋 추가
- HIGH: LOW + MIDDLE 파티션 개수만큼 오프셋 추가
- 최종 파티션 번호
- 프로필 시작 오프셋 + 상대 파티션 번호
예시 계산:
조건:
- 프로필: BLACK_HOLE (파티션 10개, 시작 오프셋 0)
- 비율 설정: LOW=6, MIDDLE=3, HIGH=1
1단계: 파티션 분배
- LOW: (6/10) * 10 = 6개 (파티션 0~5)
- MIDDLE: (3/10) * 10 = 3개 (파티션 6~8)
- HIGH: 10 - 6 - 3 = 1개 (파티션 9)
2단계: 우선순위가 MIDDLE인 경우
- 상대 파티션 = 6 + (hashCode % 3)
→ 6, 7, 8 중 하나
- 최종 파티션 = 0 (시작 오프셋) + 상대 파티션
→ 6, 7, 8 중 하나
결과와 배운 점
실제 운영 결과
하나의 토픽에서 여러 프로필의 이벤트를 처리하면서도:
- ✅ 각 검색엔진의 부하를 적절히 제어
- ✅ 우선순위가 높은 요청을 빠르게 처리
이 두 가지 요구사항을 모두 만족할 수 있게 되었습니다.
구현을 통해 깨달은 것들
1. 파티션은 “논리적 책임 분리의 도구”다
처음엔 파티션을 단순히 “성능 최적화”의 관점에서만 봤습니다. 하지만 구현하면서 깨달은 것은:
- 각 파티션에 “역할”을 부여할 수 있다
- 단순한 부하 분산을 넘어 비즈니스 의도를 파티션에 담을 수 있다는 점
- Key 설계와 파티셔너 로직으로 “프로필별, 우선순위별” 의도를 명확하게 표현
2. 좋은 추상화는 복잡성을 숨긴다
처음 파티셔너 로직은 한 메서드에 모든 계산이 들어가 있었습니다. 하지만 각 책임을 분리하면서:
ProfileKeyExtractor: Key 파싱만PartitionOffsetCalculator: 오프셋 계산만PriorityPartitionCalculator: 우선순위 파티션 계산만
이렇게 나누니 각각이 이해하기 쉬워지고, 테스트하기도 편해졌습니다.
주요 특징 정리
- 프로필별 트래픽 제어
- 각 검색엔진의 처리 능력에 맞게 파티션 수를 조절하여 부하 분산
- 우선순위 기반 처리
- 같은 프로필 내에서도 우선순위에 따라 파티션을 분리
- 긴급 요청의 빠른 처리 보장
- 유연한 설정
- application.yml을 통해 프로필별 파티션 수와 우선순위 비율을 동적으로 조정 가능
- 검색엔진의 부하 상황에 따라 실시간으로 조정 가능
- 안정적인 분산
- Key의 해시값을 이용하여 같은 우선순위 내에서 균등하게 분산
- 관심사의 분리
- 각 유틸리티 클래스가 단일 책임을 가짐
- Optional과 Stream API를 활용한 안전한 코드 작성