
GridFS의 개념
GridFS는 MongoDB에서 16MB를 초과하는 대용량 파일을 저장하기 위한 메커니즘입니다.
MongoDB의 BSON 도큐먼트 크기 제한은 16MB이기 때문에, 이를 초과하는 파일(이미지, 비디오, 오디오 등)을 저장하려면 별도의 메커니즘이 필요합니다. GridFS는 이 문제를 해결하기 위해 설계되었습니다.
MongoDB의 docs에서는 아래와 같이 설명합니다.
Info
BSON 문서 크기
최대 BSON 문서 크기는 16 메비바이트입니다.
최대 문서 크기는 단일 문서가 과도한 양의 RAM을 사용하거나, 전송 중에 과도한 대역폭을 사용하지 않도록 하는 데 도움이 됩니다.
최대 크기보다 큰 문서를 저장하기 위해 MongoDB는 GridFS API를 제공합니다.
GridFS에 대한 자세한 정보는 mongofiles 및 드라이버설명서를 참조하세요.
GridFS의 핵심 개념
- 파일 분할 저장
- 큰 파일을 작은 청크(chunk)로 나누어 저장
- 기본 청크 크기: 256KB (262,144 바이트, 커스터마이징 가능)
- 각 청크는 독립적인 도큐먼트로 chunks 컬렉션에 저장
- 예: 10MB 파일 → 약 40개의 256KB 청크로 분할
- 메타데이터 관리
- 원본 파일의 정보를 별도 컬렉션에 저장
- 파일명, 파일 크기, 업로드 시간, MIME 타입, 사용자 정의 메타데이터 등
- 두 가지 컬렉션 사용
- files 컬렉션: 파일의 메타데이터 저장소
- chunks 컬렉션: 실제 파일 데이터(바이너리) 저장소
GridFS 사용 시나리오
- 대용량 파일 저장: 비디오, 오디오, 고해상도 이미지
- 파일 버전 관리: 같은 파일의 여러 버전을 효율적으로 관리
- 범위 쿼리: 파일의 일부분만 읽기 가능
- 장점: MongoDB의 기본 기능만으로 대용량 파일 관리 가능
GridFS 아키텍처
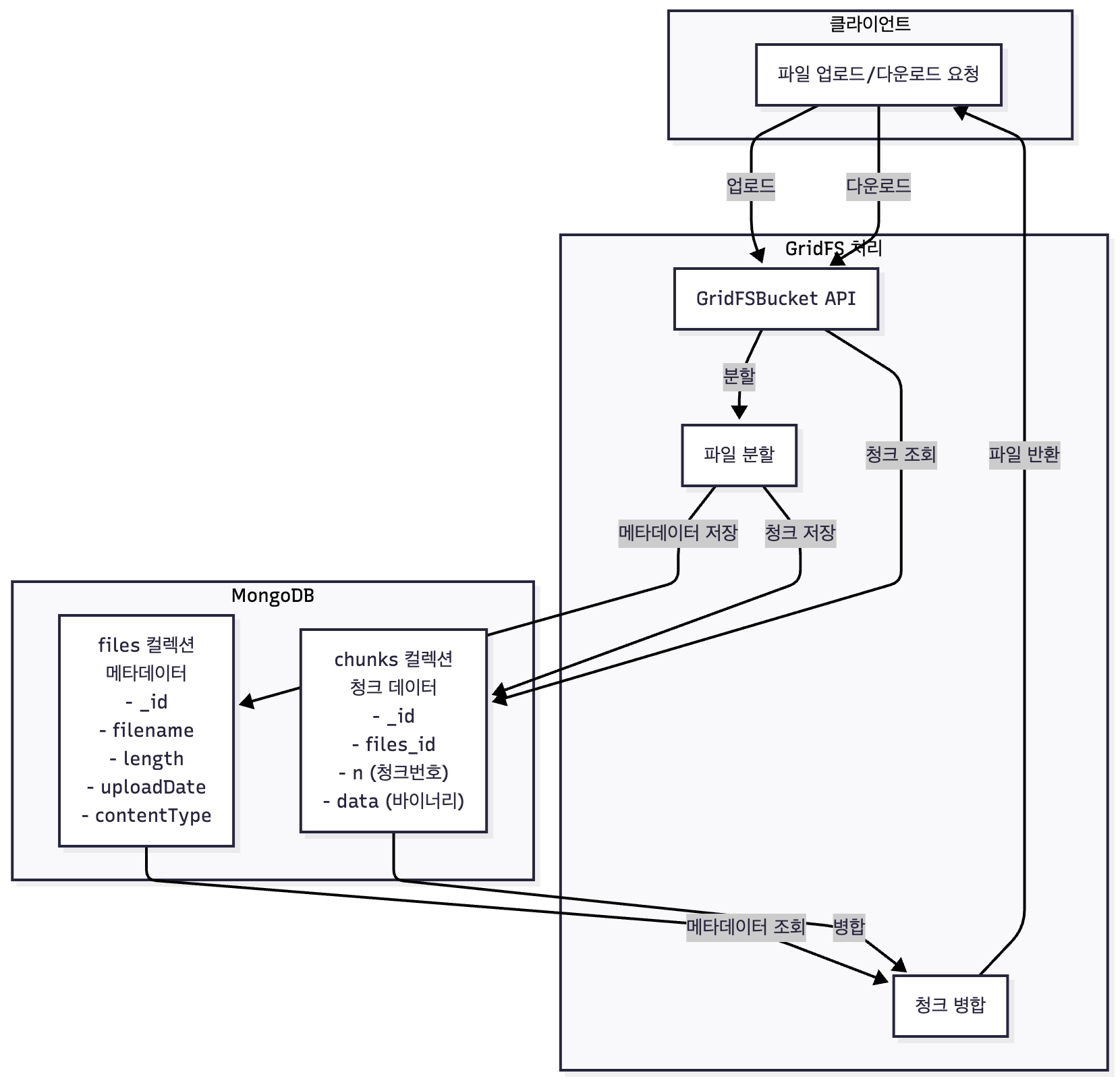
GridFS는 클라이언트와 MongoDB 사이의 미들레이어로 작동합니다. 클라이언트가 파일을 업로드하면 GridFS가 자동으로 파일을 청크로 분할하고 두 컬렉션에 저장합니다.
GridFS 파일 저장 흐름
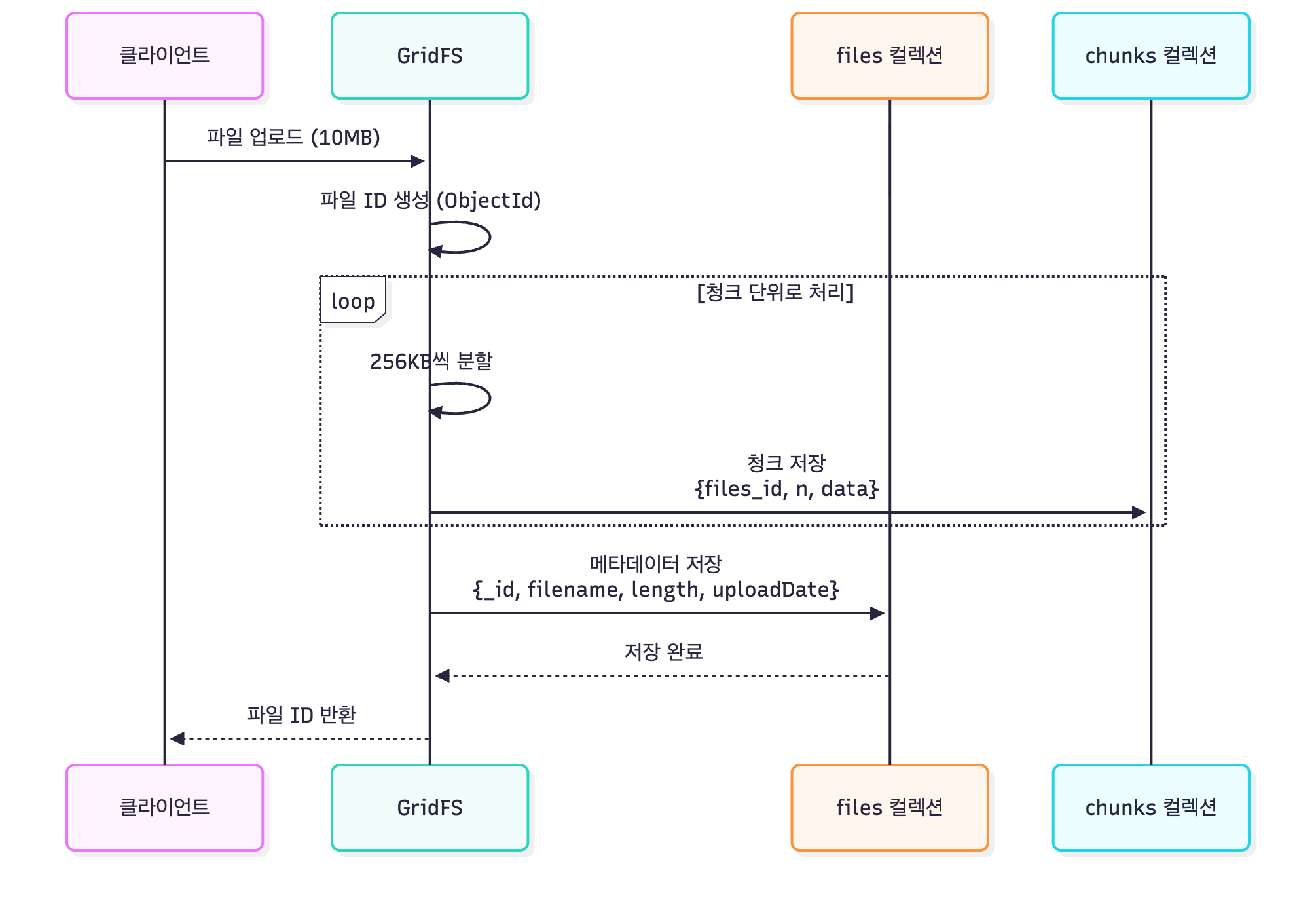
저장 흐름 상세 설명
- 파일 ID 생성: 업로드될 파일에 고유한 ObjectId가 자동으로 생성됩니다.
- 파일 분할: 원본 파일이 256KB 단위로 분할되며, 각 청크는 순서대로 n 값(0, 1, 2…)이 부여됩니다.
- 청크 저장: 각 청크는
{files_id, n, data}형태의 도큐먼트로 chunks 컬렉션에 저장됩니다. - 메타데이터 저장: 모든 청크 저장 후 파일의 메타데이터가 files 컬렉션에 저장됩니다.
- 완료: 클라이언트에게 파일 ID를 반환하여 나중에 다운로드할 때 사용하도록 합니다.
장점
- 원자성(Atomicity): 모든 청크가 저장될 때까지 메타데이터는 저장되지 않음
- 효율성: 대용량 파일도 체계적으로 관리 가능
- 유연성: 커스텀 메타데이터 추가 가능
GridFS 파일 조회 흐름
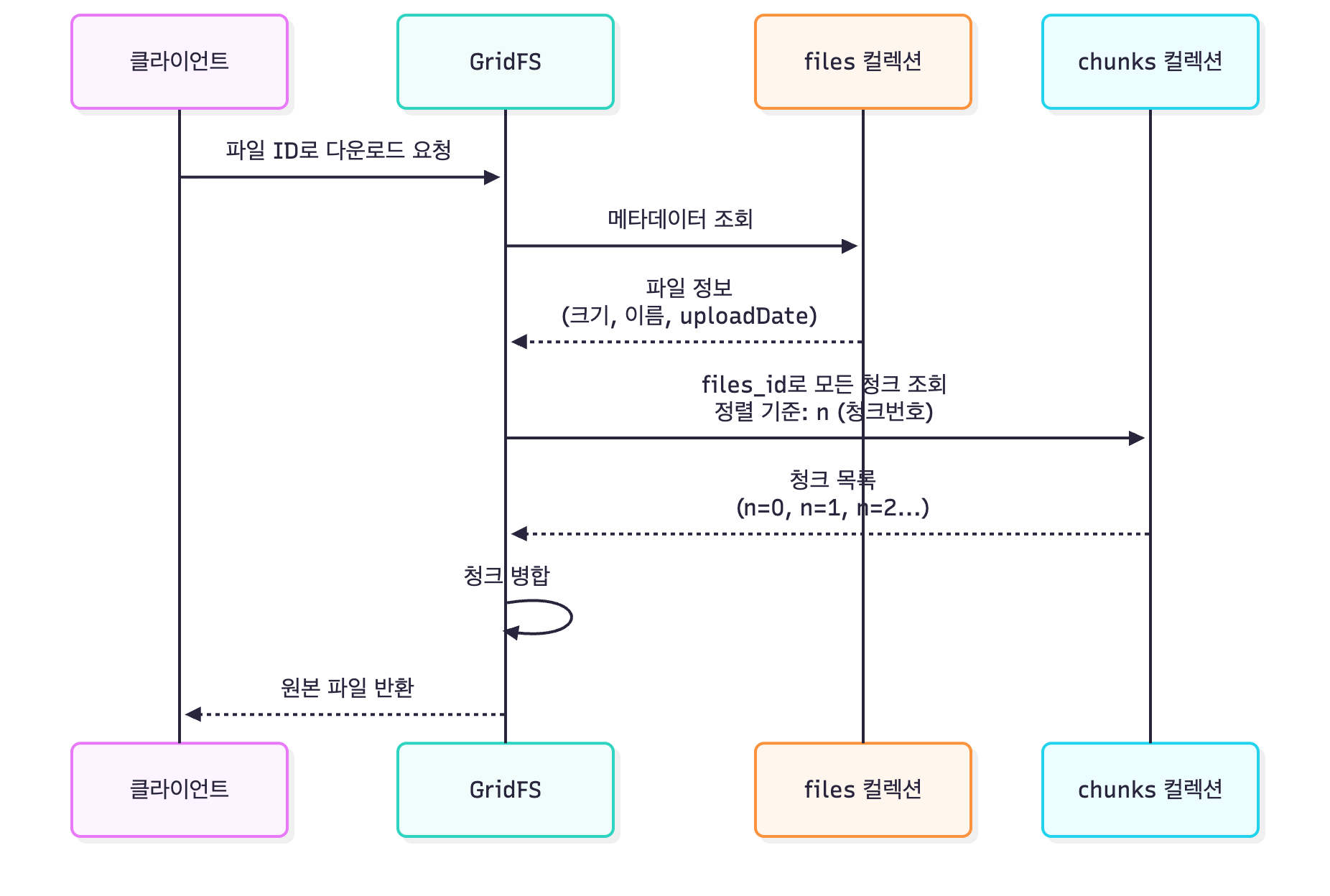
조회 흐름 상세 설명
- 메타데이터 확인: 파일 ID로 files 컬렉션에서 파일 정보를 먼저 확인합니다.
- 파일 존재 여부 확인
- 파일의 총 크기, 청크 크기, 생성일 등 확인
- 청크 데이터 수집: 같은 files_id를 가진 모든 청크를 n(청크 번호) 순서대로 조회합니다.
- 이 과정은 인덱스를 통해 최적화됩니다
-
청크 병합: 모든 청크의 바이너리 데이터를 순서대로 합쳐 원본 파일을 재구성합니다.
- 전달: 완성된 파일을 클라이언트에게 반환합니다.
주요 특징
- 부분 다운로드: 특정 바이트 범위만 다운로드 가능 (Range 요청 지원)
- 스트리밍: 모든 청크가 로드될 때까지 기다리지 않고 순차적으로 처리 가능
- 효율성: 10MB 파일이라도 메모리에 전체 로드하지 않고 청크 단위로 처리
files 컬렉션 도큐먼트 구조
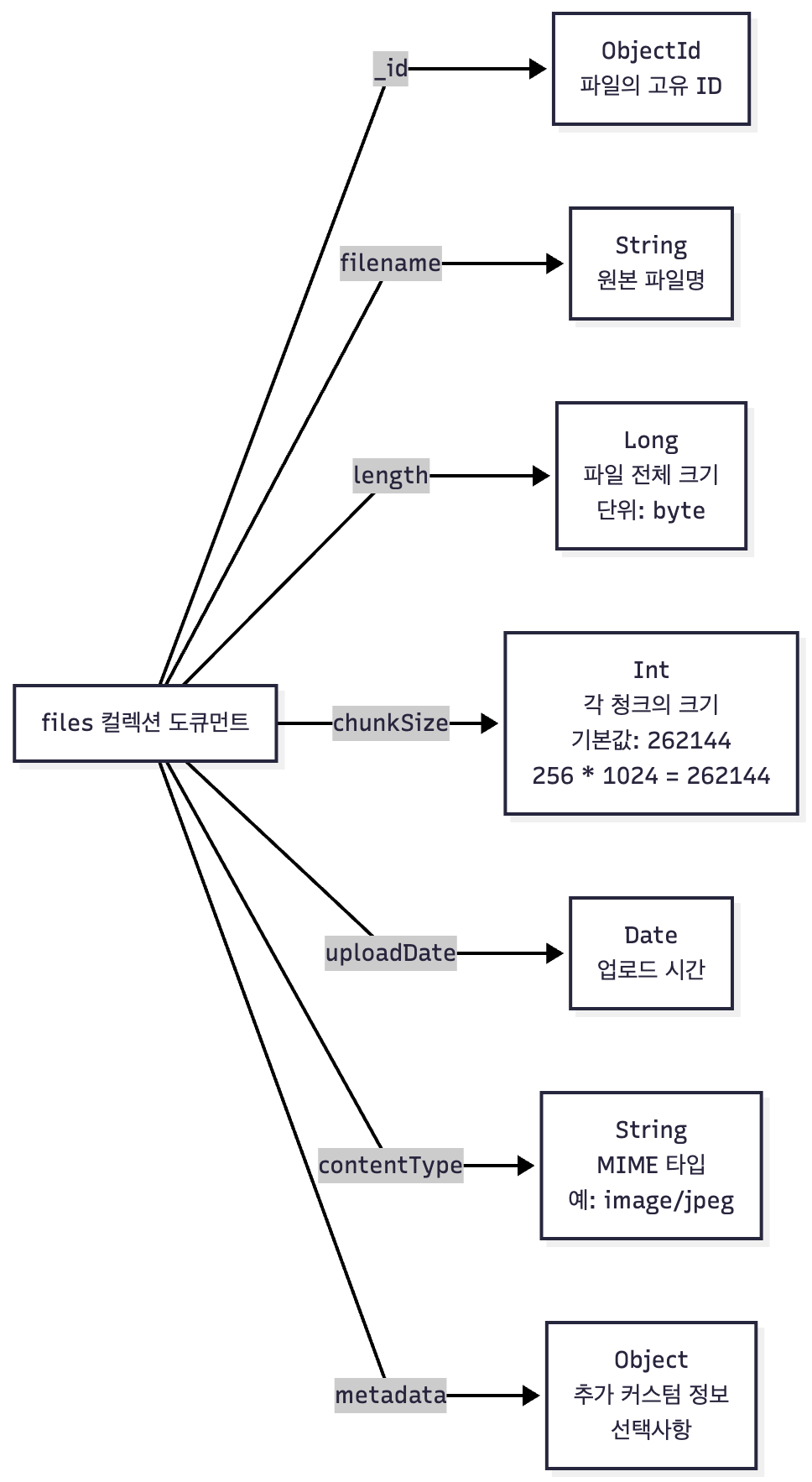
files 컬렉션 예제 도큐먼트
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"filename": "sample-video.mp4",
"length": 104857600, // 100MB
"chunkSize": 262144, // 256KB
"uploadDate": "2024-01-15T10:30:00.000Z",
"contentType": "video/mp4",
"metadata": {
"uploadedBy": "user123",
"description": "프로젝트 영상",
"tags": ["video", "project"]
}
}
각 필드의 역할
| 필드 | 타입 | 설명 |
|---|---|---|
_id |
ObjectId | 파일의 고유 식별자 |
filename |
String | 원본 파일명 (중복 가능) |
length |
Long | 파일의 전체 크기(바이트 단위) |
chunkSize |
Int | 각 청크의 크기(기본값: 262,144바이트) |
uploadDate |
Date | 파일 업로드 시간 |
contentType |
String | MIME 타입 (파일 형식 정보) |
metadata |
Object | 사용자 정의 메타데이터 (선택사항) |
chunks 컬렉션 도큐먼트 구조
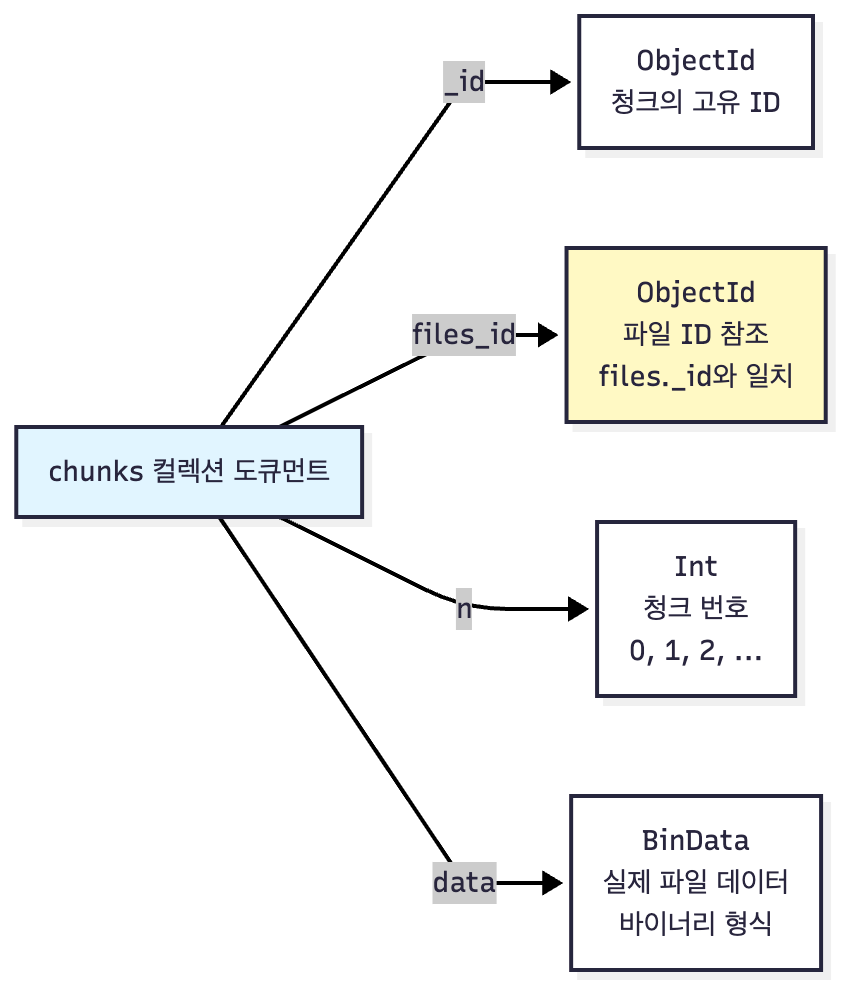
chunks 컬렉션 예제 도큐먼트
{
"_id": ObjectId("507f1f77bcf86cd799439012"),
"files_id": ObjectId("507f1f77bcf86cd799439011"),
"n": 0,
"data": BinData(0, "바이너리 데이터... (256KB)")
}
각 필드의 역할
| 필드 | 타입 | 설명 |
|---|---|---|
_id |
ObjectId | 청크의 고유 식별자 |
files_id |
ObjectId | 파일 ID (files._id와 일치) |
n |
Int | 청크 번호 (0부터 시작, 순차 증가) |
data |
BinData | 실제 파일 데이터 (BSON 바이너리 형식) |
복합 인덱스
GridFS의 효율적인 작동을 위해 아래 복합 인덱스가 자동으로 생성됩니다:
db.chunks.createIndex({ files_id: 1, n: 1 })
이 인덱스는 다음을 보장합니다:
- 같은 파일의 청크들을 빠르게 조회
- 청크 번호 순서로 정렬된 조회
- 중복 청크 방지 (유니크 인덱스)
정리
GridFS는 MongoDB에서 대용량 파일을 체계적으로 관리하기 위한 강력한 도구입니다:
- 언제 사용? 16MB 이상의 파일이 필요할 때, MongoDB 외에 별도 저장소를 두고 싶지 않을 때
- 어떻게 작동? 파일을 256KB 청크로 분할하여 저장, 메타데이터는 별도 관리
- 성능? 청크 크기, 인덱싱, 병렬 처리 등으로 최적화 가능
- 언제 피할? 매우 빈번한 파일 업로드/다운로드가 필요하면 클라우드 스토리지 고려