
상상해볼까요?
우리가 커피를 주문하기 위해 커피숍에 있다고 상상해볼까요?
하필 이 카페는 “감성” 넘치는 카페로 인스타의 유명세를 타게되었습니다. 덕분에 카페는 사람들로 붐빕니다.
주문이 너무 많이 밀려 들어와 지금은 음료를 만들어야하니 조금 있다가 다시 와달라고합니다.
그럼 여기서의 “조금 있다가”는 얼만큼의 시간을 의미할까요?
실제 카페에서는 사람들마다 나름의 “조금 있다가”의 판단을 내릴 것 입니다.
누구는 잠깐 편의점에 들렸다가 올 수도 있고, 누구는 조금의 시간도 견디지 못하고 찾아올 수도 있고, 누구는 커피 마시는걸 포기하고 대체안을 찾으러 갈 수도 있습니다.
하지만 우리의 시스템에서의 환경은 이야기가 다릅니다.
모든 네트워크에서의 요청이 그때의 상황에 맞게 다르게 동작할 수 없고 나름의 “전략”을 가지고 동작해야하기 때문입니다.
저는 여기서의 “전략”들을 알아보고 어떤 전략과 장애 상황에서 어떻게 복원해야할지 고민해보려고 합니다.
재시도 전략
위에서 설명한 조금 있다가 다시 와달라고하는 것은 시스템에서의 HTTP 요청의 재시도를 비유한 예시입니다.
그럼 여기서 재시도는 어떠한 방식으로 수행될 수 있을까요?
저는 이 전략은 간단한 PG 주문 예시와 함께 확인해보려고 합니다. 예시는 아래와 같습니다 :
사용자가 상품을 주문하는 이커머스 서비스입니다.
- 사용자가 상품을 주문합니다.
- 주문한 상품을 사용자가 카드를 통해 결제합니다.
- 결제가 완료되면 우리의 시스템은 PG사를 통해 결제를 요청합니다.
- PG 사는 결제가 완료되면 우리의 시스템에게 완료를 알립니다.
Linear backoff
Linear backoff는 이름 그대로 선형적인 시간 간격으로 재시도하는 것을 의미합니다.
가장 구현하기 단순하고 이해하기 쉬운 형태입니다.
구현 예시
아래는 간단하게 구현한 주문 로직입니다.
@Transactional
public Payment pay(PaymentCommand command) {
// 주문 생성
// 결제 금액 계산
// PG 요청
PgPayment pgPayment = pgClient.pay(payment, callbackUrl);
// 결제 저장
return paymentRepository.save(payment);
}
위 로직에서 pgClient는 Spring Open Feign을 통해 구현되어 있고, Resilience4j를 통해 재시도를 추가합니다.
@Retry(name = "pgRetry")
public PgPayment pay(Payment payment, String callbackUrl) {
return pgSimulatorClient.pay(
payment.getUserId().value(),
PgSimulatorPaymentRequest.from(payment, callbackUrl)
).getBody();
}
pgRetry에 해당하는 전략을 yml로 정의합니다.
resilience4j:
retry:
instances:
pgRetry:
max-attempts: 3
retry-exceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
fail-after-max-attempts: true
wait-duration: 1s
이 설정은 1초 간격으로 최대 3회까지 재시도합니다.
문제점: 요청 클러스터링
하지만 이 방식에는 은연중에 문제가 숨어있습니다.
카페에서 다시 찾아오라고 했던 수 많은 사람들이 모두 1초 뒤에 찾아온다면 어떻게 될까요? 카페는 모든 음료를 준비하고 주문을 받을 시간을 확보하지 못할 것입니다.
우리의 이커머스 서비스도 마찬가지입니다. 주문이 밀려 들어와 일시적으로 PG사가 결제를 처리하지 못하는 상황이 발생합니다. 이때 수천 개의 클라이언트가 동시에 같은 시간대에 재시도를 보낸다면?
특정 시간에 요청이 몰리면서 서비스 복구를 더욱 어렵게 만드는 악순환이 발생합니다.
재시도에서 가장 중요한 부분은 서비스가 복구할 시간을 벌어주는 것입니다.
하지만 Linear backoff는 요청이 동시에 몰리는 현상으로 인해 이 목표를 달성하기 어렵습니다.
Exponential backoff
위에서 재시도에서 중요한 부분은 서비스가 복구할 시간을 확보하는 것이라고 언급했습니다.
그럼 빠르게 바로 재시도하는 게 아니라 재시도의 시간을 점차적으로 늘려가는 건 어떨까요?
이 전략이 바로 Exponential backoff 전략입니다. 한국말로는 지수형 백오프 전략이라고 할 수 있습니다.
말 그대로 재시도의 간격을 1초 → 2초(2배) → 4초(2배)와 같이 지수형으로 점차 늘려 가는 것입니다.
구현 설정
resilience4j:
retry:
instances:
pgRetry:
max-attempts: 3
retry-exceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
fail-after-max-attempts: true
# Exponential Backoff 설정
wait-duration: 1s # 초기 대기 시간
enable-exponential-backoff: true # Exponential Backoff 활성화
exponential-backoff-multiplier: 2 # 배수 (1s → 2s → 4s)
이렇게 설정하면:
- 1회차 실패: 1초 대기 후 재시도
- 2회차 실패: 2초 대기 후 재시도
- 3회차 실패: 4초 대기 후 재시도
여전한 문제
이 방식도 사실 위에서 언급한 특정 시간에 요청이 몰리는 문제가 완전히 해결되지는 않습니다.
생각해보면, 만약 오후 3시에 대규모 주문이 몰려 PG사가 장애를 겪었다고 합시다. 수천 개의 주문이 동시에 1초 뒤에 재시도되고, 그 다음 모두 2초 뒤에, 그리고 4초 뒤에 재시도됩니다.
“와, 우리는 복구 시간을 벌었어!” 라고 할 수 있지만, 여전히 [3시 1초], [3시 2초], [3시 4초] 같은 특정 시점에 요청이 동시에 몰려서 들어옵니다.
AWS 문서에서 실제 그래프로 표현한 모습입니다.(출처)
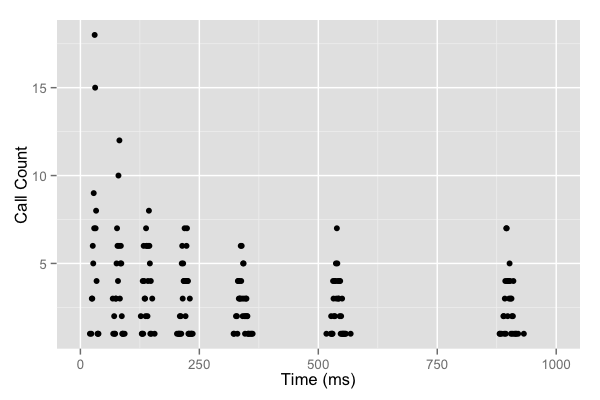
그래프를 보면 지수형으로 점점 간격이 늘어나지만, 여전히 특정 시간 간격에 요청 클러스터가 존재합니다.
AWS 문서에서는 이를 “클라이언트가 매 라운드 요청을 경쟁하고 있다(thundering herd problem)”고 표현합니다.
Exponential Jitter Backoff
이 방식은 이름에서 유추할 수 있듯이 지수형 백오프라는 걸 생각할 수 있습니다.
하지만 중간에 Jitter라는 단어가 추가되었습니다. Jitter가 무엇일까요?
Jitter를 검색하면 “디지털 신호의 타이밍이 불규칙하게 흔들리는 현상” 이라고 나옵니다.
여기서 중요한 부분은 불규칙입니다.
카페에서 다시 찾아오는 시간을 지수형으로 점점 늘리는 건 같지만, 불규칙적으로 조금씩 다르게 주문을 하러 오는 상황을 상상해보겠습니다.
이렇게 오면, 같은 시간대라도 요청이 분산되지 않을까요?
구현 설정
resilience4j:
retry:
instances:
pgRetry:
max-attempts: 3
retry-exceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
fail-after-max-attempts: true
# Exponential Backoff 설정
wait-duration: 1s # 초기 대기 시간
enable-exponential-backoff: true # Exponential Backoff 활성화
exponential-backoff-multiplier: 2 # 배수 (1s → 2s → 4s)
# Jitter 설정
enable-randomized-wait: true # Jitter 활성화
randomized-wait-factor: 0.5 # 0.5 = ±50% 랜덤 범위
이 설정에서 실제 대기 시간은:
- 1회차: 1초 ± 50% = 0.5 ~ 1.5초 (범위 내에서 랜덤)
- 2회차: 2초 ± 50% = 1 ~ 3초
- 3회차: 4초 ± 50% = 2 ~ 6초
아래는 전략을 적용했을 때의 그래프입니다.
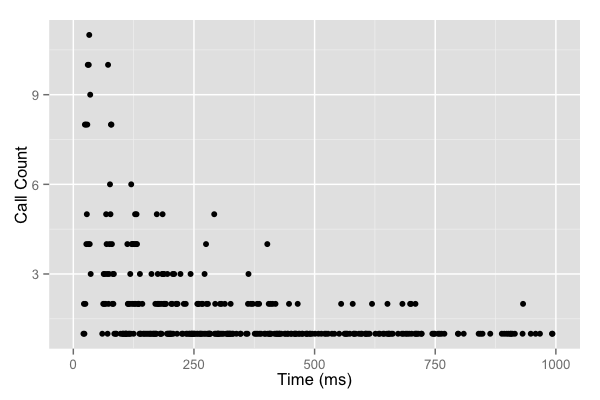
보는 것과 같이:
- 초반: 요청이 어느 정도 몰려있음 (모두 0.5~1.5초 범위)
- 점차: 요청이 고르게 분산됨 (지수형으로 분산 범위가 넓어짐)
이렇게 되면 thundering herd problem을 효과적으로 해결할 수 있습니다.
재시도를 했음에도 지속적인 오류가 발생한다면..?
카페에서 밀린 주문을 해결하다가 커피머신이 고장이 나버렸습니다…
하지만 손님들은 계속 주문을 요청하려고 찾아오고 있는 상황입니다…. 어떻게 해야할까요??
음.. 그럼 일단 손님이 주문하러 올 수 없게 “커피머신이 고장났습니다.”라는 표지판을 걸어두는 건 어떨까요?
그러면 손님들은 인식을하고 아예 주문하러 안오지 않을까요?
이와 같이 시스템에서도 더 이상 요청하지 않도록 차단할 수 있습니다.
Circuit Breaker
Circuit Breaker는 이와 같은 차단기 역할을 합니다.
사전적인 의미도 회로 차단기를 의미합니다. 즉, 과전류, 단락, 누전 등 문제가 생겼을 때 자동으로 전류를 끊는 역할을 합니다.
서비스의 장애가 발생할 것으로 보일 때, 모든 요청을 일시적으로 중단합니다. 이렇게 함으로써 실패하는 요청의 수를 줄이고, 서비스가 복구할 시간을 벌어줍니다.
상태 전이 (State Machine)
Circuit Breaker는 다음 세 가지 상태를 전환하면서 동작합니다.
Closed (정상 상태)
- 요청은 정상적으로 흐릅니다.
- 실패율을 추적합니다.
- 실패율이 임계치에 도달하면 → Open 상태로 전환
Open (장애 상태)
- 모든 요청을 즉시 거부합니다.
- 재시도하지 않고 바로 예외를 발생시킵니다.
- 설정된 대기 시간이 지나면 → Half-Open 상태로 전환
Half-Open (복구 확인 중)
- 제한된 수의 테스트 요청만 허용합니다.
- 테스트 요청이 모두 성공하면 → Closed 상태로 복귀
- 테스트 요청이 실패하면 → Open 상태로 복귀
재시도(Retry)와의 차이
| 구분 | Retry | Circuit Breaker |
|---|---|---|
| 목표 | 일시적 오류 극복 | 연쇄 장애 방지 |
| 동작 | 몇 번 재시도 | 요청 즉시 거부 |
| 언제 사용 | 네트워크 잠깐 끊김 | 서비스 완전 다운 |
| 스레드 영향 | 스레드 점유 시간 증가 | 스레드 빠르게 해제 |
이 둘은 상호 보완적이며, 함께 사용하는 것이 효과적입니다.
구현 예시
@Retry(name = "pgRetry")
@CircuitBreaker(name = "pgCircuitBreaker", fallbackMethod = "paymentFallback")
public PgPayment pay(Payment payment, String callbackUrl) {
return pgSimulatorClient.pay(
payment.getUserId().value(),
PgSimulatorPaymentRequest.from(payment, callbackUrl)
).getBody();
}
// Fallback 메서드: Circuit Breaker가 OPEN일 때 실행
private PgPayment paymentFallback(Payment payment, String callbackUrl, Exception ex) {
log.warn("PG 결제 서비스 장애 발생, 결제 보류 처리: {}", payment.getOrderId());
// 결제를 보류 상태로 변경
// 나중에 배치 작업으로 재처리하거나, 관리자에게 알림
return PgPayment.pending(payment.getOrderId());
}
상세 설정 파일
resilience4j:
circuitbreaker:
instances:
pgCircuitBreaker:
# 실패율 계산 방식
sliding-window-type: COUNT_BASED # 최근 N개 호출 기준
sliding-window-size: 10 # 최근 10개 호출로 판단
failure-rate-threshold: 60 # 60% 이상 실패 시 OPEN
# OPEN → HALF-OPEN 전환
wait-duration-in-open-state: 10s # 10초 후 복구 테스트
# HALF-OPEN 상태 설정
permitted-number-of-calls-in-half-open-state: 2 # 2개만 테스트 요청
# 느린 요청도 실패로 취급
slow-call-duration-threshold: 2s # 2초 이상이면 느린 호출
slow-call-rate-threshold: 50 # 50% 이상이 느리면 OPEN
각 설정값 상세 설명
sliding-window-size: 10- 실패율을 계산할 때 최근 10개 호출만 고려합니다.
- 과거 모든 호출 이력을 고려하지 않으므로, 일시적 오류에 더 빨리 반응합니다.
failure-rate-threshold: 60- 최근 10개 중 6개(60%) 이상이 실패하면 서킷을 엽니다.
- 설정값이 높을수록: 더 많은 실패를 견디고, 레이턴시 중심
- 설정값이 낮을수록: 빨리 차단하고, 시스템 보호 중심
wait-duration-in-open-state: 10s- 서킷이 OPEN된 후, 10초 동안은 모든 요청이 즉시 거부됩니다.
- 10초 후에 자동으로 HALF-OPEN으로 전환되어 복구를 테스트합니다.
permitted-number-of-calls-in-half-open-state: 2- HALF-OPEN 상태에서 최대 2개의 테스트 요청만 허용합니다.
- 첫 2개가 성공하면 CLOSED로 복귀, 하나라도 실패하면 다시 OPEN
slow-call-duration-threshold: 2s- 응답 시간이 2초를 초과하면 “느린 호출”로 분류합니다.
- 실제로 실패하지 않았어도 시스템 부하의 신호입니다.
slow-call-rate-threshold: 50- 최근 호출 중 50% 이상이 느린 호출이면 서킷을 엽니다.
- 예: 10개 중 5개 이상이 2초 이상 걸리면 OPEN
그럼 Circuit Breaker가 OPEN되면 요청을 보내지 않고 어떻게 처리될까요?
PG사의 경우는 토스 페이먼츠같은 곳에 장애가 발생했다면, 다른 PG사에 요청을 하거나 fallback처리를 할 수 있습니다.
fallback은 우리가 정의한 값으로 반환하게 하여 나중에 처리하거나 장애를 발생 시키지 않고 사용자에게 문제 상황을 알릴 수 있습니다.
결론은..?
이 글의 시작부터 카페와 PG사에 대한 내용으로 재시도와 복원의 전략에 대해서 알아봤습니다.
그럼 중간에 저는 그런 고민이 생겼습니다.
“아니 그럼 무조건 Exponential Jitter Backoff 방식으로 Retry하고 Circuit braker를 적용하면 좋은거야?”
사실 그렇지는 않을 것이라고 저는 스스로 판단했습니다.
일단 Exponential Jitter Backoff 방식은 3~4회 정도 시도한다고 했을 때, 다른 전략과 차별점이 있습니다.
하지만 이 방식은 지수형으로 대기 시간이 점점 늘어나기 때문에 오랜 시간 스레드를 점유하는 문제가 발생하고 서버의 성능을 전체적으로 나쁘게 할 수 있습니다.
위에 예시와 같이 PG는 사용자의 “돈” 과 관련된 문제 이므로 최대한 성공을 보장하기 위해 적용할 수 있지만, 이정도로 중요한 비즈니스가 아닌 경우에는 짧은 간격으로 Linear backoff 전략을 적용하는 것이 더 좋을 수 있겠다 생각이 들었습니다.
Circuit Breaker는 사실 있으면 그냥 좋다! 왜냐면 장애가 전파되는 것을 막을 수 있으니까! 특히나 분산 시스템 환경에서는!
하지만 충분히 많은 대용량 트래픽이 아니라면 없어도 무방하지 않을까? 라는 생각을 하게되었습니다.
항상 모든 기술은 적용하기 전에 우리 비즈니스에 요구사항 분석이 먼저인 것 같습니다.