
상품 집계
저는 이전에 Kafka를 활용해 실시간으로 일일 상품 집계를 저장하도록 구현했습니다.
상품 집계에는 아래와 같은 데이터들이 존재합니다.
- 상품의 좋아요 수
- 상품의 조회 수
- 상품의 구매 수
즉, 위 행위의 이벤트가 발생할때마다 상품의 일일 집계 데이터를 갱신하여 일일통계 데이터를 수집했습니다.
이제 이 일일 통계 데이터를 통해 주간, 월간 통계를 Spring Batch를 통해 구현하고자 했습니다.
Spring Batch를 활용한 이유는 “대용량 데이터에 대한 처리”와 “실시간성이 중요하지 않은 작업”이라는 판단하에 가장 적절하다고 판단했습니다.
Partitioner
일일 집계 데이터는 어느정도의 데이터가 쌓일까요?
실제로 우리 서비스가 어느정도의 사람이 사용하는지, 어떤 목적을 위해 사용하는지에 따라 실제 배포하기 전에는 추측하기 어렵습니다.
저는 그래서 이 집계라는 데이터가 얼마나 “쉽게” 쌓일 수 있는지 고민해봤습니다.
위 집계에 데이터를 보면 “상품 조회 시”에도 데이터가 쌓인다는 걸 알 수 있습니다.
즉, 너무나도 쉽게 쌓일 수 있는 데이터라고 판단했습니다.
그래서 이 데이터의 규모를 “수십만건” 혹은 “수백만건”이라고 가정해보겠습니다.
Spring Batch에는 Reader, Processor, Writer를 통해 데이터를 읽고 처리합니다.
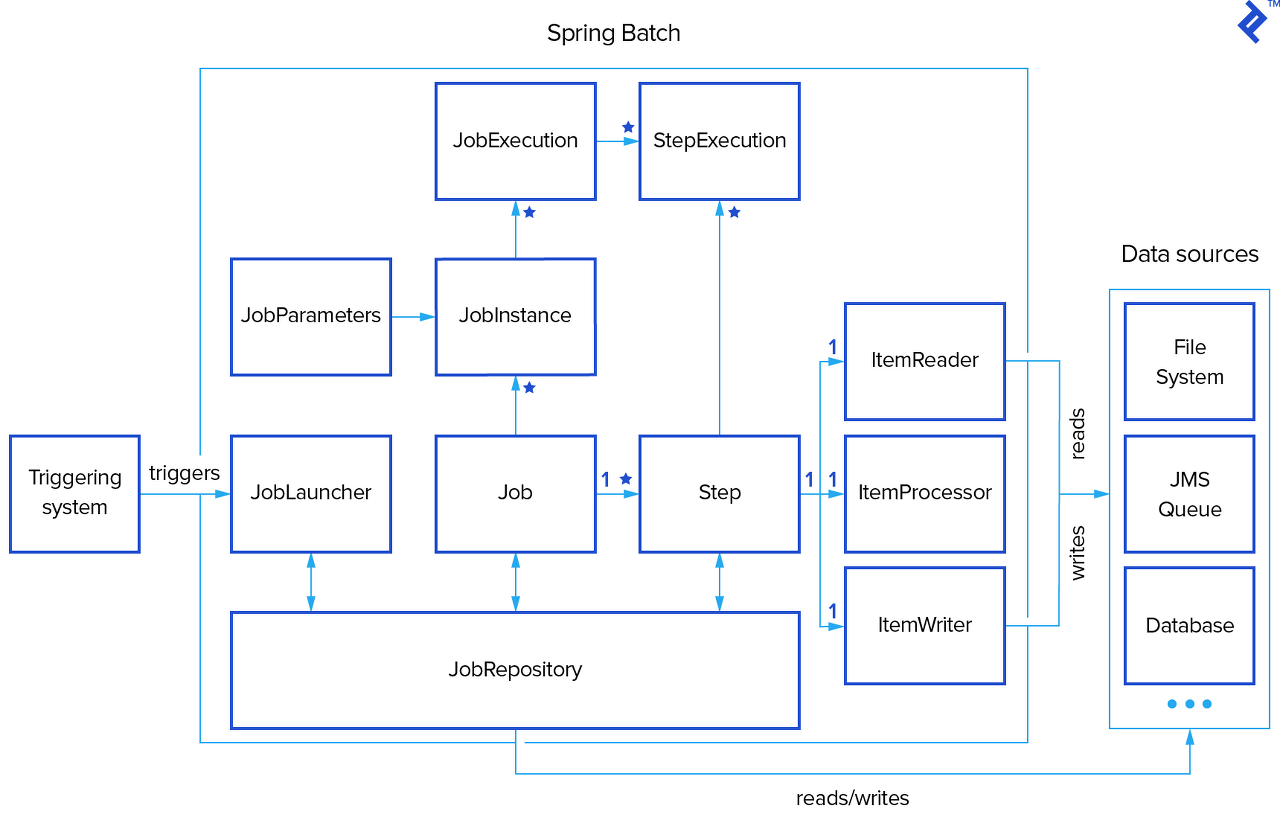
하나의 Step에서 이 모든 데이터를 처리하는데 문제가 없을까요?
물론 멀티 쓰레드를 통해 Step을 실행하여 성능을 크게 향상 시킬 수 있을 것입니다.
하지만 위와 같이 너무나도 많은 데이터를 처리해야하는 경우
“작업을 여러 Step으로 나누어 병렬로 처리할 수 있지 않을까?” 라는 생각을 하게 되었습니다.
그러다가 Spring Batch에서 Partitioning기능을 찾아보게 되었습니다.
파티셔닝은 매니저(마스터) Step이 다량에 데이터를 처리하기 위해 지정된 수의 작업자 (Worker) Step으로 일감을 분리하여 처리합니다.
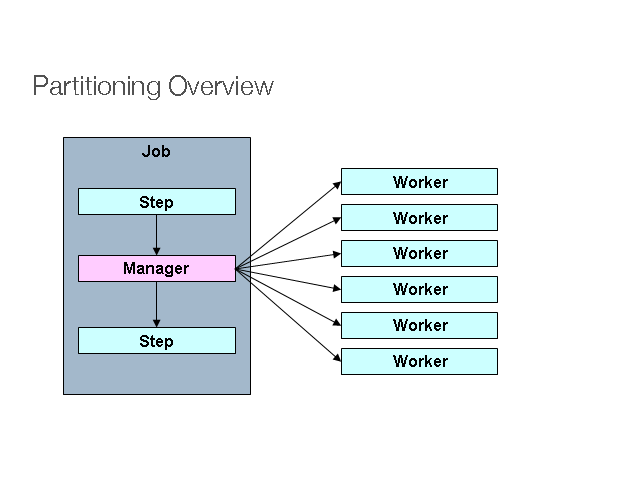
어떻게 구현해볼 수 있을까?
파티셔닝을 구현하기위해 Spring Batch의 Partitioner 인터페이스를 구현해야 합니다.
@FunctionalInterface
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
여기서 ExecutionContext는 Job을 실행하면서 필요한 데이터를 지속가능한 상태로(데이터베이스 등) 저장할 수 있도록 Spring Batch 에서 지원하는 key/value 데이터를 담는 공간입니다.
그리고 gridSize는 우리가 작업을 몇개의 Step (Worker)로 분할하여 작업할 것인지에 대한 크기입니다.
저는 이 인터페이스를 아래와 같이 구현했습니다.
@Component
@StepScope
@RequiredArgsConstructor
public class WeeklyProductMetricBatchPartitioner implements Partitioner {
private final DailyProductMetricRepository dailyProductMetricRepository;
@Value("#{jobParameters['startDate']}")
private String startDateParam;
@Value("#{jobParameters['endDate']}")
private String endDateParam;
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
LocalDate startDate = LocalDate.parse(startDateParam);
LocalDate endDate = LocalDate.parse(endDateParam);
Long totalCount = dailyProductMetricRepository.countDistinctProductIdsBy(startDate, endDate);
if (totalCount == 0) {
return Collections.emptyMap();
}
long targetSize = (totalCount / gridSize) + 1;
Map<String, ExecutionContext> partitions = new HashMap<>();
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putLong("partitionOffset", i * targetSize);
context.putLong("partitionLimit", targetSize);
context.putString("startDate", startDateParam);
context.putString("endDate", endDateParam);
partitions.put("partition" + i, context);
}
return partitions;
}
}
- 집계할 일일 통계의 시작 날짜와 끝 날짜를 파라미터로 받습니다.
- 데이터베이스를 통해 이 날짜 사이에 처리해야할 상품의 총 갯수를 조회합니다.
- 전체 갯수와
gridSize를 통해offset과limit을 계산하여 파티션별로 할당합니다.
ItemReader
이제 Reader를 통해 파티셔닝으로 나누어진 데이터를 조회해야합니다.
ExecutionContext를 통해 데이터를 가져오기위해 ItemStreamReader 인터페이스를 상속받은 Reader를 구현합니다.
ItemStreamReader는 ItemStream과 ItemReader를 상속받고 있습니다.
public interface ItemStreamReader<T> extends ItemStream, ItemReader<T> {
}
public interface ItemStream {
default void open(ExecutionContext executionContext) throws ItemStreamException {
}
default void update(ExecutionContext executionContext) throws ItemStreamException {
}
default void close() throws ItemStreamException {
}
}
@FunctionalInterface
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
그럼 구현은 아래와 같이 할 수 있습니다.
@RequiredArgsConstructor
public class WeeklyProductMetricBatchReader implements ItemStreamReader<ProductMetricAggregation> {
private final DailyProductMetricRepository dailyProductMetricRepository;
private Iterator<ProductMetricAggregation> iterator;
@Override
public void open(@NonNull ExecutionContext executionContext) {
LocalDate startDate = LocalDate.parse(executionContext.getString("startDate"));
LocalDate endDate = LocalDate.parse(executionContext.getString("endDate"));
long partitionOffset = executionContext.getLong("partitionOffset");
long partitionLimit = executionContext.getLong("partitionLimit");
this.iterator = dailyProductMetricRepository.findAggregatedBy(startDate, endDate, partitionOffset, partitionLimit)
.iterator();
}
@Nullable
@Override
public ProductMetricAggregation read() {
if (Objects.isNull(iterator) || !iterator.hasNext()) {
return null;
}
return iterator.next();
}
}
ExecutionContext를 통해 파티셔닝된 offset과 limit을 가져옵니다.- offest과 limit을 통해 처리할 데이터를 집계하여 조회합니다.
ItemWriter
이 집계 배치에서는 Processor를 따로 구현하지 않았습니다.
구현하지 않은 이유는 따로 필요해 보이지 않고 Writer에서 한번에 더 실행하는 것이 효율적으로 보였습니다.
건당 복잡한 로직이 있으면 구현했을 것 같지만, 조회한 데이터를 단순 집계 데이터로 변환하는 작업이였기 때문입니다.
ItemWriter 또한 ExecutionContext를 가져오기 위해 ItemStreamWriter를 상속받아 구현합니다.
@StepScope
@Component
@RequiredArgsConstructor
public class WeeklyProductMetricBatchWriter implements ItemStreamWriter<ProductMetricAggregation> {
private final WeeklyProductMetricRepository repository;
private YearMonthWeek yearMonthWeek;
@Override
public void open(@NonNull ExecutionContext executionContext) {
LocalDate startDate = LocalDate.parse(executionContext.getString("startDate"));
this.yearMonthWeek = YearMonthWeek.from(startDate);
}
@Override
public void write(@NonNull Chunk<? extends ProductMetricAggregation> chunk) {
List<WeeklyProductMetric> weeklyMetrics = chunk.getItems().stream()
.map(aggregation -> aggregation.to(yearMonthWeek))
.toList();
repository.bulkUpsert(weeklyMetrics);
}
}
데이터베이스의 저장은 많은 데이터를 빠르게 저장하기위해 jdbc의 batchUpdate()를 사용하여 저장했습니다.
이로써 파티셔닝으로 나누어진 데이터를 처리할 Step이 구현이 되었습니다.
Spring Batch 설정
그럼 이제 이 파티셔너와 Step을 어떻게 동작 시킬 것인지에 대한 Configuration을 정의해야합니다.
먼저 Worker Step의 설정은 아래와 같이 설정했습니다.
@Bean
public Step collectDailyMetricStep(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemStreamReader<ProductMetricAggregation> synchronizedWeeklyProductMetricReader,
WeeklyProductMetricBatchWriter weeklyProductMetricBatchWriter,
@Value("${batch.weekly-product-metric.chunk:50}") int chunk
) {
return new StepBuilder("collectDailyMetricStep", jobRepository)
.<ProductMetricAggregation, ProductMetricAggregation>chunk(chunk, transactionManager)
.reader(synchronizedWeeklyProductMetricReader)
.writer(weeklyProductMetricBatchWriter)
.taskExecutor(asyncTaskExecutor())
.faultTolerant()
.retry(DataAccessException.class)
.build();
}
여기서 봐야할 부분은 taskExecutor와 reader입니다.
TaskExecutor는 Worker Step의 chunk단위의 작업을 병렬로 처리 하기위해 AsyncTaskExecutor로 구현했습니다.
@Bean
public TaskExecutor asyncTaskExecutor() {
SimpleAsyncTaskExecutor executor = new SimpleAsyncTaskExecutor("weekly-product-metric-batch-");
executor.setVirtualThreads(true);
executor.setConcurrencyLimit(20);
return executor;
}
하지만 여기서 생기는 문제가 있습니다.
여러 쓰레드가 동시에 ItemReader에 자원에 접근하여 동일한 데이터를 중복 처리할 수 있었습니다.
이 문제를 이미지로 보면 아래와 같습니다.
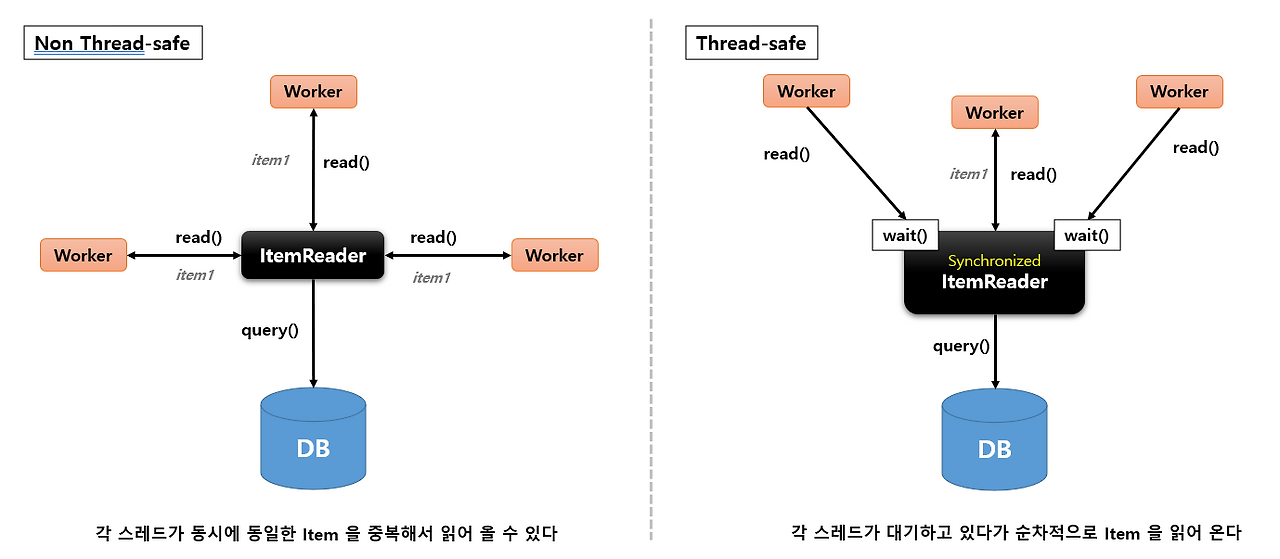
즉, thread-safe한 ItemReader를 구현해야했고 방법은 아래와 같습니다.
@Bean
@StepScope
public ItemStreamReader<ProductMetricAggregation> synchronizedWeeklyProductMetricReader(
DailyProductMetricRepository dailyProductMetricRepository
) {
WeeklyProductMetricBatchReader reader = new WeeklyProductMetricBatchReader(dailyProductMetricRepository);
return new SynchronizedItemStreamReaderBuilder<ProductMetricAggregation>()
.delegate(reader)
.build();
}
우리가 구현한 ItemReader를 SynchronizedItemStreamReader를 통해 감싸서 해결이 가능합니다.
이 SynchronizedItemStreamReader는 아래와 같이 ReentrantLock을 통해 동시성을 제어합니다.
public class SynchronizedItemStreamReader<T> implements ItemStreamReader<T>, InitializingBean {
private ItemStreamReader<T> delegate;
private final Lock lock = new ReentrantLock();
@Override
@Nullable public T read() throws Exception {
this.lock.lock();
try {
return this.delegate.read();
}
finally {
this.lock.unlock();
}
}
}
이로써 Worker Step의 작업또한 멀티쓰레드를 통해 병렬로 실행할 수 있게 되었습니다.
이제는 파티셔너와 이 Worker Step의 관계를 정의해주어야합니다.
구현은 아래와 같이 구성했습니다.
@Bean
public Step partitionDailyMetricStep(
JobRepository jobRepository,
Step collectDailyMetricStep,
WeeklyProductMetricBatchPartitioner partitioner,
@Value("${batch.weekly-product-metric.partition.grid-size:4}") int gridSize
) {
return new StepBuilder("partitionDailyMetricStep", jobRepository)
.partitioner("collectDailyMetricStep", partitioner)
.step(collectDailyMetricStep)
.taskExecutor(asyncTaskExecutor())
.gridSize(gridSize)
.build();
}
step: Worker Step을 정의합니다.taskExecutor: Worker Step들을 실행할taskExecutor를 정의합니다.- 위에서 정의한
AsyncTaskExecutor로 정의했습니다.
- 위에서 정의한
gridSize: 파티셔닝으로 나눌 Worker Step의 갯수를 정의합니다. (default 값은 4입니다.)
이로써 Worker Step의 작업과 Step의 실행 모두 병렬로 수행할 수 있었습니다.
테스트
이제 정상 동작하는지 테스트를 했습니다. 검증할 목록은 아래와 같았습니다.
- 주간 통계 데이터가 올바른 개수로 저장이 되야한다.
- 주간 통계 데이터가 올바르게 합산되어 저장되어야한다.
- 배치를 여러번 실행하더라도 멱등하게 처리되어야한다.
- 월요일부터 일요일까지의 메트릭이 주간 메트릭으로 집계된다.
데이터 저장 개수 검증
@Test
@DisplayName("파티션 배치가 올바르게 분할되어 동시 처리된다")
void shouldPartitionDataCorrectly() throws Exception {
// given
LocalDate startDate = LocalDate.of(2025, 1, 6);
LocalDate endDate = LocalDate.of(2025, 1, 12);
// 100개 상품 × 7일 = 700개 메트릭
List<DailyProductMetric> dailyMetrics = new ArrayList<>();
for (int productNum = 1; productNum <= 100; productNum++) {
for (int dayOffset = 0; dayOffset < 7; dayOffset++) {
LocalDateTime createdAt = startDate.plusDays(dayOffset).atStartOfDay();
DailyProductMetric metric = DailyProductMetricFixture.createWith(
String.valueOf(productNum),
productNum,
(long) productNum * 2,
(long) productNum * 3,
createdAt
);
dailyMetrics.add(metric);
}
}
// 데이터 저장
dailyProductMetricRepository.saveAll(dailyMetrics);
// when
JobParameters jobParameters = new JobParametersBuilder()
.addString("startDate", startDate.toString())
.addString("endDate", endDate.toString())
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(weeklyProductMetricJob, jobParameters);
// then - 100개 상품 모두 저장되었는지 확인
Integer savedCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM weekly_product_metrics",
Integer.class
);
assertThat(savedCount).isEqualTo(100);
// 중복 없이 각 상품별 1개씩만 저장되었는지 확인
Integer distinctProductCount = jdbcTemplate.queryForObject(
"SELECT COUNT(DISTINCT product_id) FROM weekly_product_metrics",
Integer.class
);
assertThat(distinctProductCount).isEqualTo(100);
}
통계 합산 검증
@Test
@DisplayName("메트릭 값이 올바르게 합산되어 저장된다")
void shouldSumMetricsCorrectly() throws Exception {
LocalDate startDate = LocalDate.of(2025, 1, 6);
LocalDate endDate = LocalDate.of(2025, 1, 12);
// // 상품 1: 7일 동안 좋아요 10씩 (총 70) List<DailyProductMetric> dailyMetrics = new ArrayList<>();
for (int day = 0; day < 7; day++) {
LocalDateTime createdAt = startDate.plusDays(day).atStartOfDay();
DailyProductMetric metric = DailyProductMetricFixture.createWith("1", 10, 20, 30, createdAt);
dailyMetrics.add(metric);
}
dailyProductMetricRepository.saveAll(dailyMetrics);
// when
JobParameters jobParameters = new JobParametersBuilder()
.addString("startDate", startDate.toString())
.addString("endDate", endDate.toString())
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(weeklyProductMetricJob, jobParameters);
// then
Long likeCount = jdbcTemplate.queryForObject(
"SELECT like_count FROM weekly_product_metrics WHERE product_id = 1",
Long.class
);
Long viewCount = jdbcTemplate.queryForObject(
"SELECT view_count FROM weekly_product_metrics WHERE product_id = 1",
Long.class
);
Long salesCount = jdbcTemplate.queryForObject(
"SELECT total_sales_count FROM weekly_product_metrics WHERE product_id = 1",
Long.class
);
assertThat(likeCount).isEqualTo(70L); // 10 * 7
assertThat(viewCount).isEqualTo(140L); // 20 * 7
assertThat(salesCount).isEqualTo(210L); // 30 * 7
}
멱등성 검증
@Test
@DisplayName("UPSERT가 정상 동작하여 중복 저장을 방지한다")
void shouldHandleUpsertCorrectly() throws Exception {
// given
LocalDate startDate = LocalDate.of(2025, 1, 6);
LocalDate endDate = LocalDate.of(2025, 1, 12);
// 초기 데이터: 상품 1에 대한 7일 메트릭 저장
List<DailyProductMetric> dailyMetrics = new ArrayList<>();
for (int day = 0; day < 7; day++) {
LocalDateTime createdAt = startDate.plusDays(day).atStartOfDay();
DailyProductMetric metric = DailyProductMetricFixture.createWith("1", 10, 20, 30, createdAt);
dailyMetrics.add(metric);
}
dailyProductMetricRepository.saveAll(dailyMetrics);
// when - 첫 번째 배치 실행
JobParameters jobParameters1 = new JobParametersBuilder()
.addString("startDate", startDate.toString())
.addString("endDate", endDate.toString())
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(weeklyProductMetricJob, jobParameters1);
// 같은 데이터로 두 번째 배치 실행
JobParameters jobParameters2 = new JobParametersBuilder()
.addString("startDate", startDate.toString())
.addString("endDate", endDate.toString())
.addLong("timestamp", System.currentTimeMillis() + 1000)
.toJobParameters();
jobLauncher.run(weeklyProductMetricJob, jobParameters2);
// then - 2개가 아닌 1개만 저장되어야 함
Integer savedCount = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM weekly_product_metrics WHERE product_id = 1",
Integer.class
);
assertThat(savedCount).isEqualTo(1);
}
처리 기간 검증
@Test
@DisplayName("저번주 월요일부터 일요일까지의 일일 메트릭을 주간 메트릭으로 집계한다")
void shouldAggregateWeeklyMetricFromDailyMetric() throws Exception {
// given
LocalDate startDate = LocalDate.of(2025, 1, 6); // 월요일
LocalDate endDate = LocalDate.of(2025, 1, 12); // 일요일
// 저번주 데이터 준비 (5개 상품 × 7일 = 35개 메트릭)
List<DailyProductMetric> dailyMetrics = new ArrayList<>();
for (int productNum = 1; productNum <= 5; productNum++) {
for (int dayOffset = 0; dayOffset < 7; dayOffset++) {
LocalDateTime createdAt = startDate.plusDays(dayOffset).atStartOfDay();
DailyProductMetric metric = DailyProductMetricFixture.createWith(
String.valueOf(productNum),
10L + dayOffset, // likeCount
20L + dayOffset, // viewCount
30L + dayOffset, // totalSalesCount
createdAt
);
dailyMetrics.add(metric);
}
}
// 데이터 저장
dailyProductMetricRepository.saveAll(dailyMetrics);
// when
JobParameters jobParameters = new JobParametersBuilder()
.addString("startDate", startDate.toString())
.addString("endDate", endDate.toString())
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(weeklyProductMetricJob, jobParameters);
// then
Integer savedWeeklyMetrics = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM weekly_product_metrics",
Integer.class
);
assertThat(savedWeeklyMetrics).isEqualTo(5);
}
이 검증들을 통해 성능도 중요하지만, 정확하게 처리됐는지도 확인할 수 있었습니다.
마무리
사실 가장 의미있는 방식은 일단 단순하게 구현을 하고, 성능상 문제가 생겼을 때 개선하는 방향이라고 생각합니다.
하지만 뻔하게 너무 많은 데이터가 들어올 것 같다라고 판단됐을때는 그에 따른 준비를 하는 것도 중요하다고 생각합니다.
이 경계 사이에서 판단을 하는 것이 “실력”이 아닐까? 라는 생각이 들었습니다.
사실 파티셔너를 구현하여 Step을 나누지 않더라도 Step을 병렬로 처리하는 방식만으로도 충분히 빠른 서비스를 운영할 수 있습니다.
파티셔닝에 대한 장점은 또 Worker Step의 코드 변경 없이 마스터 Step에 파티셔너만 추가하여 구현할 수 있다는 점입니다.
파티셔닝이 의미가 없다고 판단되면 큰 코드 변경없이 Job을 실행 시킬 수 있습니다.
즉, 파티셔닝없이 구현을 하다가 필요하다 판단되는 시점에 추가하여 구현할 수 있습니다.