
개요
문제: MongoDB 16MB 제한의 벽
표절검사 서비스에서는 특정 문서가 어디서 표절을 했는지에 대한 정보, 즉 후보군 데이터를 저장합니다.
- 어떤 문서는 수만 개의 후보군을 저장해야 함
- 많게는 수십 MB를 초과하는 데이터가 발생
우리는 이 대용량 데이터를 저장하기 위해 MongoDB를 선택했습니다. 하지만 새로운 문제가 나타났습니다.
MongoDB의 근본적인 제약: 16MB 제한
MongoDB는 단일 문서의 최대 크기를 16MB로 제한합니다. 이는 BSON(Binary JSON) 형식의 근본적인 제약입니다.
왜 이런 제약이 있을까요?
- 단일 문서가 과도한 RAM을 사용하는 것을 방지
- 전송 중에 과도한 대역폭을 사용하지 않도록 제어
- 데이터베이스의 안정성을 위한 설계 결정
솔루션 탐색: 왜 GridFS를 선택했는가?
데이터를 저장하는 방법으로 여러 선택지를 검토했습니다:
- Sharding (MongoDB 샤딩)
- 장점: MongoDB 내부에서 처리
- 단점: 복잡한 설정, 쿼리 복잡도 증가
- S3 같은 외부 스토리지
- 장점: 무제한 크기 지원
- 단점: 별도 시스템 의존, 네트워크 비용 증가, 데이터 일관성 관리 복잡
- GridFS (MongoDB 기본 제공) ✅ 최종 선택
- 장점: MongoDB와 통합, 투명한 저장/로드, 추가 시스템 불필요
- 단점: MongoDB 내에서 처리되는 추가 오버헤드
결론적으로, MongoDB 생태계 내에서 기본 제공하는 GridFS가 가장 깔끔했습니다.
더 자세한 GridFS 개념은 GridFS란? 포스트를 참조해주세요.
이 글에서는 GridFS의 실제 적용 과정과 설계 결정을 설명하겠습니다.
구현 아키텍처
전체 흐름도
요청
↓
SearchedCandidatesRepositoryImpl
├─ findByCandidateJobId()
│ ├─ repository.findByCandidateJobId()
│ └─ searchedCandidatesEnricher.enrichWithGridFsDataIfNeeded()
│ ├─ save()
│ └─ searchedCandidatesPersister.persist()
│
└─ findAllByCandidateGroupId()
└─ [enrichWithGridFsDataIfNeeded() × N]
컴포넌트별 책임
| 컴포넌트 | 책임 | |
|---|---|---|
| SearchedCandidatesRepositoryImpl | Repository 인터페이스 구현, 전체 흐름 조율 | |
| SearchedCandidatesPersister | 데이터 저장 시 candidates 크기 GridFS 분기 처리 | |
| SearchedCandidatesEnricher | GridFS에 저장된 데이터 로드 및 도메인 객체 복원 | |
| SearchedCandidatesGridFSStorage | GridFS 저장 로직 | |
| GridFsCandidatesLoader | GridFS에서 데이터 읽기 |
각 컴포넌트 상세 구현
SearchedCandidatesRepositoryImpl
@Component
@RequiredArgsConstructor
public class SearchedCandidatesRepositoryImpl implements SearchedCandidatesRepository {
private final SearchedCandidatesMongoRepository repository;
private final SearchedCandidatesEnricher searchedCandidatesEnricher;
private final SearchedCandidatesPersister searchedCandidatesPersister;
@Override
public Optional<SearchedCandidates> findByCandidateJobId(CandidateJobId candidateJobId) {
Optional<SearchedCandidatesMongoEntity> findSearchedCandidates = repository.findByCandidateJobId(candidateJobId.value());
return findSearchedCandidates.flatMap(
searchedCandidatesEnricher::enrichWithGridFsDataIfNeeded
);
}
@Override
public SearchedCandidates save(SearchedCandidates searchedCandidates) {
return searchedCandidatesPersister.persist(searchedCandidates);
}
@Override
public List<SearchedCandidates> findAllByCandidateGroupId(CandidateGroupId candidateGroupId) {
return repository.findAllByCandidateGroupId(candidateGroupId.value()).stream()
.map(searchedCandidatesEnricher::enrichWithGridFsDataIfNeeded)
.filter(Optional::isPresent)
.map(Optional::get)
.toList();
}
}
책임:
- Domain Repository 인터페이스 구현
- 저장소 계층 조율
- 조회/저장 메서드 제공
SearchedCandidatesPersister
@Component
@RequiredArgsConstructor
public class SearchedCandidatesPersister {
private final SearchedCandidatesMongoRepository repository;
private final SearchedCandidatesGridFSStorage gridFsStorage;
public SearchedCandidates persist(SearchedCandidates searchedCandidates) {
try {
// 먼저 일반 저장 시도
SearchedCandidatesMongoEntity entity = SearchedCandidatesMongoEntity.from(searchedCandidates);
return repository.save(entity).toDomain();
} catch (BsonMaximumSizeExceededException exception) {
// 16MB 초과 시 GridFS로 자동 전환
String gridFsFileId = gridFsStorage.store(searchedCandidates);
SearchedCandidatesMongoEntity entity = SearchedCandidatesMongoEntity.withGridFS(
searchedCandidates,
gridFsFileId );
return repository.save(entity).toDomain();
}
}
}
책임:
- 자동 분기 처리: 16MB 초과 예외 감지
- 투명한 저장: 클라이언트는 GridFS 사용 여부를 알 필요 없음
- 적응형 저장소: 데이터 크기에 따라 자동으로 저장 방식 선택
동작 흐름:
1. 작은 데이터 (< 16MB) → 일반 저장
2. 큰 데이터 (>= 16MB) → BsonMaximumSizeExceededException 발생
3. 예외 처리 → GridFS로 전환
4. GridFS에 저장된 파일 ID만 메인 문서에 저장
SearchedCandidatesGridFSStorage
@Component
@RequiredArgsConstructor
public class SearchedCandidatesGridFSStorage {
private final GridFsTemplate gridFsTemplate;
public String store(SearchedCandidates searchedCandidates) {
// 1. 도메인 객체를 엔티티로 변환
List<CandidateMongoEntity> candidates = searchedCandidates.fetchCandidates().stream()
.map(CandidateMongoEntity::from)
.toList();
// 2. JSON 직렬화
String jsonData = JsonUtils.convertToString(candidates);
// 3. 파일명 생성 (추적용)
String fileName = "candidates_" + searchedCandidates.getCandidateJobId().value() + ".json";
// 4. 메타데이터 설정 (나중에 조회 시 사용)
Document metadata = new Document(
"candidate_job_id", searchedCandidates.getCandidateJobId().value()
);
// 5. GridFS에 저장
ObjectId fileId = gridFsTemplate.store(
new ByteArrayInputStream(
jsonData.getBytes(StandardCharsets.UTF_8)
),
fileName, "application/json", metadata );
// 6. 파일 ID 반환 (메인 문서에서 참조)
return fileId.toString();
}
}
책임:
- 도메인 객체를 JSON으로 직렬화
- GridFS에 바이너리 데이터로 저장
- 파일 ID 반환 (데이터베이스 참조용)
저장 과정:
SearchedCandidates 객체
↓CandidateMongoEntity 리스트로 변환
↓JSON 직렬화
↓ByteArrayInputStream으로 변환
↓GridFS 저장 (자동으로 255KB 청크로 분할)
↓ObjectId 반환 (String으로 변환)
GridFsCandidatesLoader
@Component
@RequiredArgsConstructor
public class GridFsCandidatesLoader {
private final GridFsTemplate gridFsTemplate;
public Optional<Candidates> loadCandidatesFromGridFs(String gridFsFileId) {
try {
// 1. 파일 ID로 GridFS에서 파일 메타데이터 조회
GridFSFile gridFSFile = gridFsTemplate.findOne(
Query.query(
Criteria.where("_id").is(new ObjectId(gridFsFileId))
)
);
if (gridFSFile == null) {
return Optional.empty();
}
// 2. GridFS 리소스 획득
GridFsResource resource = gridFsTemplate.getResource(gridFSFile);
// 3. InputStream으로 JSON 읽기
try (InputStream inputStream = resource.getInputStream()) {
// 4. JSON을 Candidate 엔티티 리스트로 역직렬화
List<CandidateMongoEntity> candidateMongoEntities = JsonUtils.convertStreamToObject(
inputStream, new TypeReference<>() { }
);
// 5. 도메인 객체로 변환
return Optional.of(new Candidates(
candidateMongoEntities.stream()
.map(CandidateMongoEntity::toDomain)
.toList()
));
}
} catch (IOException | IllegalArgumentException exception) {
// 파일 손상이나 읽기 실패 시 빈 Optional 반환
return Optional.empty();
}
}
}
책임:
- GridFS에서 파일 ID로 데이터 로드
- JSON을 도메인 객체로 역직렬화
- 예외 처리 (파일 손상, 없는 파일)
로드 과정:
파일 ID (String) ↓ObjectId로 변환 후 GridFS 검색
↓GridFSFile 메타데이터 획득
↓GridFsResource로 InputStream 획득
↓JSON 역직렬화
↓도메인 객체로 매핑
↓Optional<Candidates> 반환
SearchedCandidatesEnricher
@Component
@RequiredArgsConstructor
public class SearchedCandidatesEnricher {
private final GridFsCandidatesLoader gridFsCandidatesLoader;
public Optional<SearchedCandidates> enrichWithGridFsDataIfNeeded(
SearchedCandidatesMongoEntity entity) {
// gridFsFileId가 있으면 GridFS에서 로드, 없으면 엔티티의 candidates 사용
if (Objects.nonNull(entity.getGridFsFileId())) {
// GridFS에서 로드된 candidates로 도메인 객체 재구성
return gridFsCandidatesLoader.loadCandidatesFromGridFs(
entity.getGridFsFileId()
).map(candidates -> entity.toDomain().withCandidates(candidates)
);
}
// GridFS 미사용: 기본 엔티티 변환
return Optional.of(entity.toDomain());
}
}
책임:
- 저장 방식에 따른 투명한 데이터 로드
- GridFS 여부 판단 (gridFsFileId 확인)
- 도메인 객체 복원
동작 흐름:
SearchedCandidatesMongoEntity
↓gridFsFileId 확인
├─ null → 일반 데이터 사용 (toDomain())
└─ 존재 → GridFS 로드
├─ GridFsCandidatesLoader 호출
├─ JSON 파싱 및 객체 생성
└─ candidates로 도메인 객체 복원
데이터 흐름 (시퀀스)
저장 흐름 (Save)
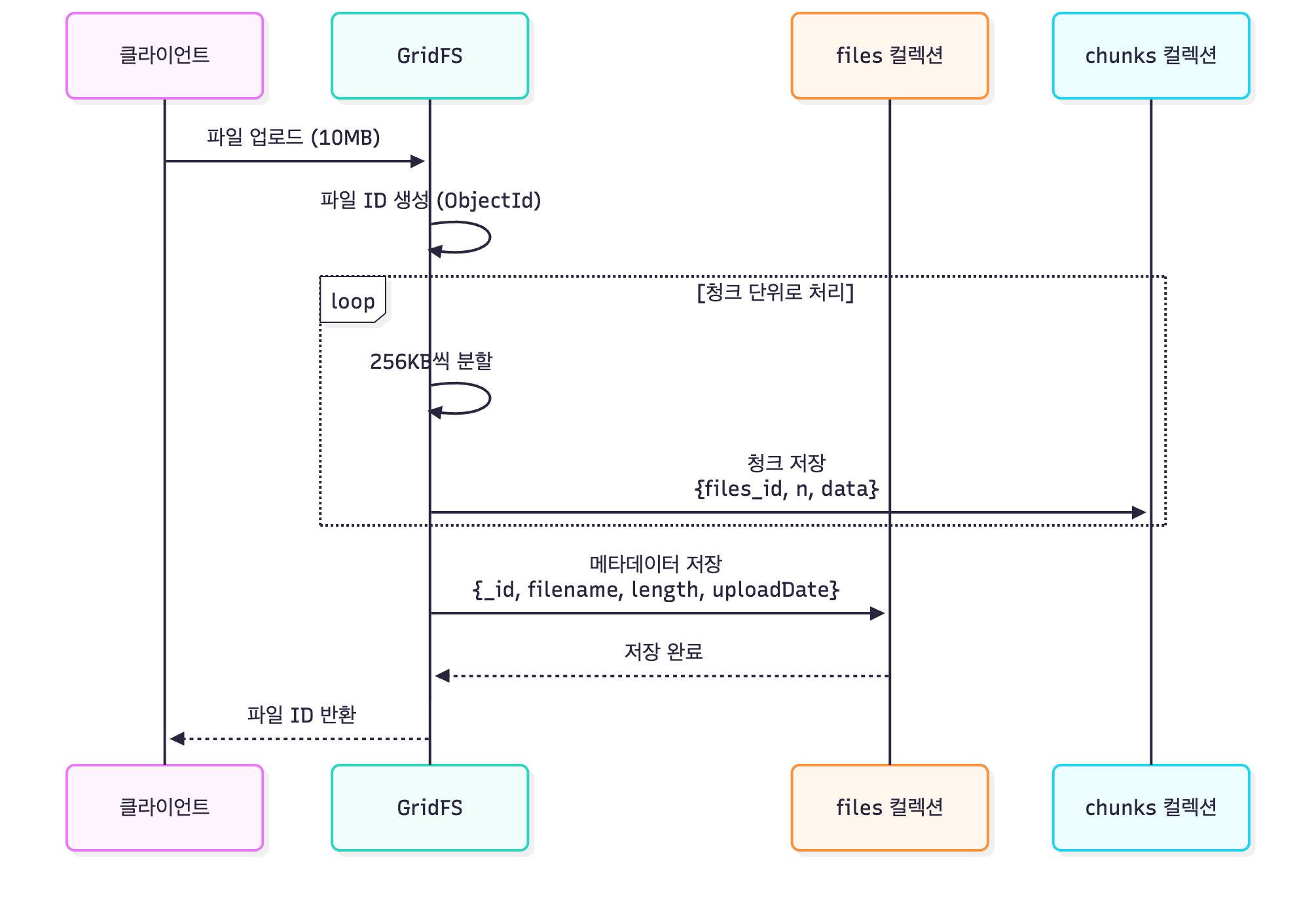
Flow 설명
| 단계 | 설명 |
|---|---|
| 1단계 | 클라이언트가 SearchedCandidates 저장 요청 |
| 2단계 | RepositoryImpl에서 Persister로 위임 |
| 3단계 | Persister가 먼저 일반 저장 시도 |
| 4-1단계 (작은 데이터) | 16MB 미만이면 일반 저장 완료 |
| 4-2단계 (큰 데이터) | 16MB 이상이면 BsonMaximumSizeExceededException 발생 |
| 5단계 | GridFSStorage로 데이터 저장 |
| 6단계 | GridFS 파일 ID 획득 |
| 7단계 | 파일 ID를 포함한 엔티티로 재생성 |
| 8단계 | 작은 메인 문서만 데이터베이스에 저장 |
조회 흐름 (Find)
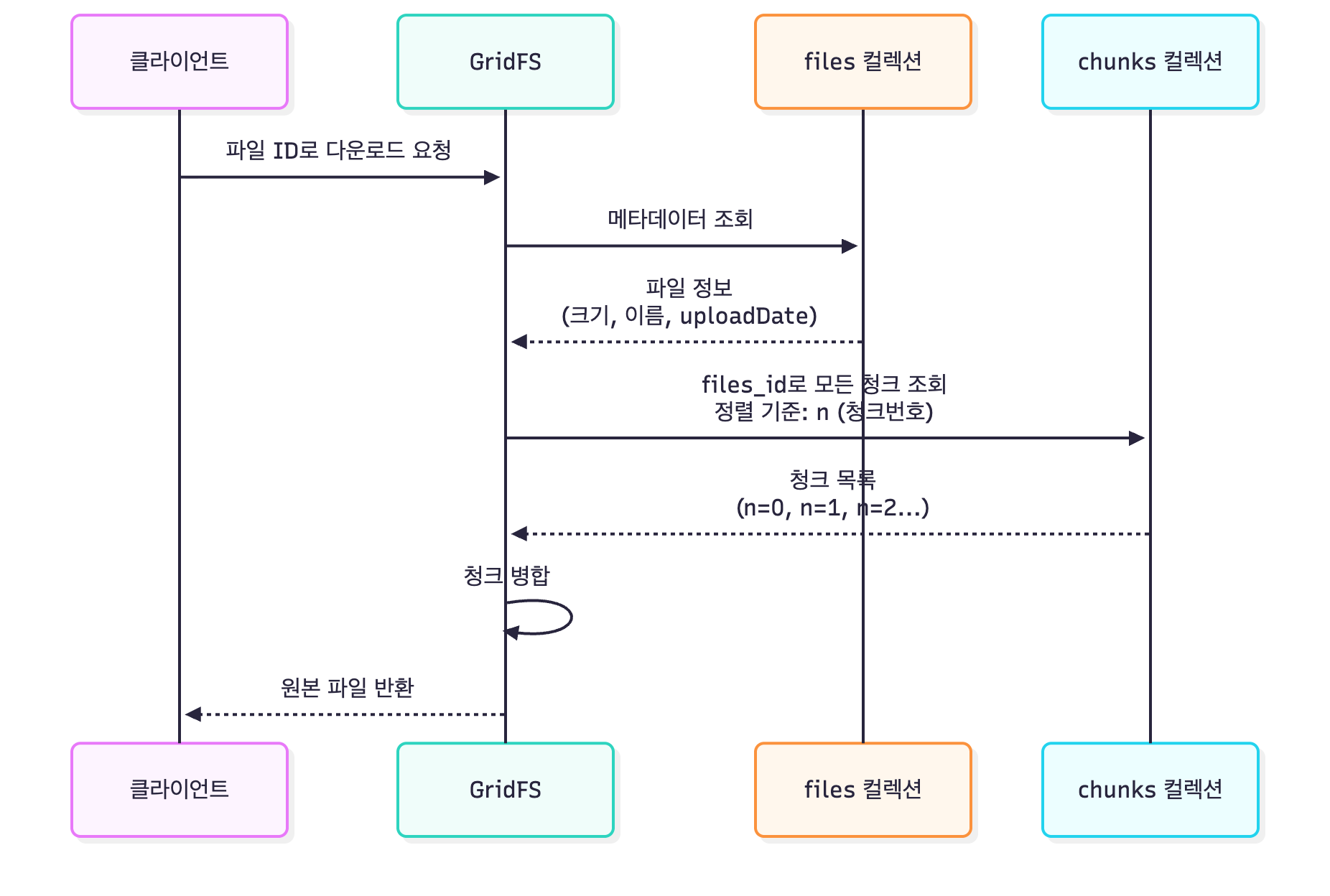
Flow 설명
| 단계 | 설명 |
|---|---|
| 1단계 | 클라이언트가 CandidateJobId로 조회 요청 |
| 2단계 | MongoDB에서 메인 문서 조회 |
| 3단계 | Enricher에서 데이터 복원 |
| 4-1단계 (일반 데이터) | gridFsFileId가 null이면 직접 변환 |
| 4-2단계 (GridFS 데이터) | gridFsFileId가 존재하면 GridFS에서 로드 |
| 5단계 | GridFS 파일 ID로 데이터 검색 |
| 6단계 | InputStream 기반 스트리밍으로 JSON 읽기 |
| 7단계 | JSON 역직렬화 및 도메인 객체 변환 |
| 8단계 | 복원된 candidates로 최종 객체 구성 |
MongoDB 컬렉션 구조
searched_candidates (메인 컬렉션)
{
_id: ObjectId("..."),
candidateJobId: "job_123", candidateGroupId: "group_456", profileName: "LINKEDIN", candidates: [ // 작은 데이터 (<16MB) {
sentenceKey: "sent_1",
key: "key_1",
wordCount: 100,
copyWordCount: 50,
copyRatio: 50,
uri: "https://...",
text: "...",
duplicatedDocumentCount: 2,
metadata: { ... }
}
],
gridFsFileId: null, // 작은 데이터면 null createdAt: ISODate("..."),
lastModifiedAt: ISODate("...")
}
// 또는 대용량 데이터
{
_id: ObjectId("..."),
candidateJobId: "job_789", candidateGroupId: "group_999", profileName: "LINKEDIN", candidates: null, // null (GridFS에서 로드)
gridFsFileId: "507f191e810c19729de860ea", // GridFS 파일 ID createdAt: ISODate("..."),
lastModifiedAt: ISODate("...")
}
fs.files (GridFS 메타데이터)
{
_id: ObjectId("507f191e810c19729de860ea"),
filename: "candidates_job_789.json",
contentType: "application/json",
uploadDate: ISODate("2024-10-17T10:30:45.000Z"),
length: 15728640, // 약 15MB metadata: {
candidate_job_id: "job_789"
}
}
fs.chunks (GridFS 데이터)
{
_id: ObjectId("..."),
files_id: ObjectId("507f191e810c19729de860ea"),
n: 0, // 청크 번호
data: BinData(0, "...") // 255KB 바이너리 데이터
}
{
_id: ObjectId("..."),
files_id: ObjectId("507f191e810c19729de860ea"),
n: 1, // 다음 청크
data: BinData(0, "...")
}
// ... n이 계속 증가하면서 저장
성능 특성
| 항목 | 설명 |
|---|---|
| 저장 성능 | 소규모(<16MB): O(1), 대규모: 청크 분할로 인한 약간의 오버헤드 |
| 조회 성능 | 소규모: O(1), 대규모: InputStream 기반 순차 읽기 |
| 메모리 효율 | GridFS 사용: 전체 파일을 메모리에 올리지 않음 (스트리밍) |
| 확장성 | 무제한 크기 지원 (256MB 초과 파일도 가능) |
참고
메타데이터 활용
// 메타데이터로 조회 가능
db.fs.files.find({ "metadata.candidate_job_id": "job_123" })
GridFS 삭제
// GridFS 파일 삭제 필요 시
gridFsTemplate.delete(Query.query(Criteria.where("_id").is(new ObjectId(fileId))));
설계를 통해 배운 것들
1. 투명성(Transparency)의 가치
이 구현에서 가장 중요한 설계 결정은 GridFS 사용을 클라이언트에게 투명하게 만드는 것이었습니다.
처음에는 클라이언트 코드에서 GridFS 여부를 판단하도록 설계했습니다:
// Before: 클라이언트가 GridFS를 알아야 함 (X)
if (isLarge(data)) {
gridFsStorage.store(data);
} else {
repository.save(data);
}
하지만 최종 설계는 저장소 계층이 모든 판단을 담당합니다:
// After: 클라이언트는 그냥 저장하면 됨 (O)
repository.save(data); // 알아서 GridFS로 전환됨
이렇게 하면:
- 클라이언트는 간단: 저장/로드만 하면 됨
- 변경에 유연: GridFS 전환 기준을 서버 코드로 변경 가능
- 테스트가 쉬움: Mock 저장소로 대체 가능
2. 예외 기반 분기의 트레이드오프
우리는 BsonMaximumSizeExceededException을 감지하여 GridFS로 전환합니다.
장점:
- 먼저 일반 저장을 시도해서 정상 데이터는 빠르게 저장
- 예외 상황에만 GridFS 사용 → 평균 성능 좋음
단점:
- 데이터 크기를 먼저 알 수 없으면 예외까지 대기
- 예외 처리 오버헤드 발생
더 나은 방법도 있습니다:
// 데이터 크기를 미리 계산해서 선택
if (estimateSize(data) > THRESHOLD) {
storeWithGridFS(data);
} else {
storeDirectly(data);
}
하지만 우리의 경우, 데이터 구조가 복잡해서 크기 예측이 어려웠습니다. 따라서 예외 기반 분기가 더 실용적이었습니다.
3. 메타데이터의 중요성
GridFS에 메타데이터를 저장한 것이 나중에 큰 도움이 되었습니다:
metadata: {
candidate_job_id: "job_123"
}
이덕분에:
- 추적 가능: 어떤 파일이 어떤 작업의 데이터인지 알 수 있음
- 조회 최적화: 메인 문서의 ID 없이도 GridFS에서 직접 검색 가능
- 삭제 안전성: 고아 데이터 정리 가능
초반에는 메타데이터를 “선택사항”으로 봤지만, 실제 운영에서는 필수사항이 되었습니다.